Icebergのデータ層にs3a使わずにOzoneでデータ分析に最適なofs/FSOを使いたい話
この記事は MicroAd Advent Calendar 2023 と Distributed computing (Apache Spark, Hadoop, Kafka, ...) Advent Calendar 2023 の25日目の記事です。
アドカレも今日で最後になりました。会社の方は全部埋まって記事も投稿出来てるので一安心ですが、Distributed computing アドカレの方は寂しい状態です。とは言え、参加してくれた皆さんには感謝しかないし、どの記事も良かった!
ただ、せっかくなので、出来るだけ空いてるところを埋めていきたいところ。
では、今日のお題に入っていきます。
前提
続きを読むRKE2ノードのCiliumを使ったeBPFな帯域制限をする話
この記事は MicroAd Advent Calendar 2023 と Kubernetes Advent Calendar 2023 の5日目の記事です。
オンプレあるあるな悩みとして、データセンターと外の通信にはインターネットを経由する都合、1つのアプリで契約している帯域を専有してしまいインターネット通信が輻輳1 (ふくそう)し、他のシステムの本番環境に影響させてしまう事があったりします。
今回は、RKE22 で構築したKubernetesノードにて、Pod発の通信に対して帯域制限をかける方法について紹介します。
- 環境
- 種明かし
- 利用できるか確認する
- Nodeのセットアップ
- RKE2のみの場合
- Rancherを使ってクラスターをCreateする場合
- CiliumのBandwidth Managerが有効になっているか確認
- Podに帯域制限をかけるには?
- 実際に試してみてる
- 最後に
- おまけ
- 「輻輳」とは、ネットワークトラフィックが集中して、通信速度が低下すること↩
- docs.rke2.io↩
Icebergテーブルの内部構造について
この記事は MicroAd Advent Calendar 2023 と Distributed computing (Apache Spark, Hadoop, Kafka, ...) Advent Calendar 2023 の1日目の記事です。
今年もアドカレの季節がやってきました🎄
今回は、ここ数年でデータ界隈で盛り上がっているOpen Table FormatのIcebergテーブルについて書いていきます。 Hiveテーブルとの比較とか、Icebergテーブルの特徴(Time Travel や Rollback、Hidden Partitioning、Full Schema Evolution等)については、あっちこっちで大分こすられてます。
そこで、Icebergテーブルの特徴がなぜ実現できているのかについて知るために、内部構造がどうなっているかを掘り下げていきます。 また、内部構造を知ることでIcebergテーブルを利用する際の運用面についてもイメージしやすくなってくると思います。
では、始めていきます。
(´-`).。oO(ソースコードまでは掘り下げできなかったので、ソースコードコードリーディングとかしたいですね。私はほぼ読めませんけど。)
- はじめに
- Icebergテーブル:データ層
- データ層(データファイル)
- データ層(削除ファイル)
- データ層(Puffinファイル)
- Icebergテーブル:メタデータ層
- Icebergテーブル:カタログ
- 最後に
- 参考
- 補足
TiDBをHadoop管理者視点でデータ基盤としての使い所を考えてみる
この記事は MicroAd Advent Calendar 2022 と Distributed computing (Apache Spark, Hadoop, Kafka, ...) Advent Calendar 2022 の25日目の記事です。
今年のアドカレも最終日になりました。
とは言え、Distributed computing Advent Calendar 2022 の方はエントリが結構残ってるので、引き続き空いてる枠への参加をお待ちしてます!
今回は、Hadoopクラスタ管理者の視点で、データ基盤としてTiDBの使い所について考えてみます。 また、データ基盤の規模感としては、ペタバイトレベルのクラスタ、1テーブルあたり最大100TBクラスを想定しています。
- TiDBとは
- データ基盤として見たときにTiDBに求めるもの
- 構築する場合の運用しやすさ
- TiUPコマンドがとにかく便利
- 負荷テストやベンチ、Sandbox環境も簡単。TiUPならね。
- KubernetesでのTiDB構築について
- データの可用性について
- データベースやテーブルサイズに対する上限
- テーブルサイズや行数について
- パーティションについて
- テーブルのデータ型やデータ操作について
- スキーマ進化出来るか(テーブル定義やパーティションの変更しやすさ)
- 構築する場合の運用しやすさ
- 使い所を考える
- さいごに
BigData向けワークロード(Spark/Flink)に適したKubernetesカスタムスケジューラ Apache YuniKorn について
この記事は Distributed computing Advent Calendar 2022 の5日目の記事です1。
今回は、今年の5月にApache Software Foundation (ASF)のTop-Level Project (TLP)2になった Apache YuniKorn について紹介します。
YuniKornの概要
YuniKornは、YARNで要求されていたワークロードに関するリソーススケジューリングをKubernetesで利用できるよう作成したようです。
YARN(Yet Another Resource Negotiator)とは、Hadoopクラスタ内のジョブのスケジュールやリソース管理する基盤です。
YARN自体に馴染みのない方は以下を見るとYuniKornも理解しやすいです。
YARNの概要とFAIRスケジューラについてはこちら。
www.slideshare.net
Capacityスケジューラについてはこちら。
また、Hadoop3エコシステムはだいたいJava(一部C++など)で実装されていますが、YuniKornはgolangで実装されています。
YuniKornの由来と読み方
YuniKornの名前の由来は "Y"をYARN(フロントエンドのyarnじゃないよ)、"K"をKubernetes、"Uni"をUnifiedから取っているそうです。 また、発音は[‘ju:nikɔ:n]となり、ロゴにもなっているUnicornと同じです4。
なぜYuniKornが必要なのか?
BigDataやMLでのワークロードは、大量のデータを処理しなければならないので、レイテンシよりもスループットが非常に大事です。
また、この手のワークロードはマルチテナントで利用されることが多く、リソーススケジューリングにする要求は複雑になりがちです。
例えば、以下のような事が普通に求められ、これまで、YARNにて対応してきました(YARNスゴイヨ)。
- 大事なバッチにはクラスタの半分のリソースを優先して割り当てる
- 部門Aのアドホックなワークロードにはクラスタリソースの10%までを割り当てる
- ただし、バッチなど優先したいワークロードがなくヒマしているなら、10%を超えて使ってもOK
- とはいえ、メインのバッチが始まったらワークロードをプリエンプティブする
- さらに、部門Aのリソースのうち、半分はBさんが優先して使ってOK
そして、これまでHadoopエコシステムのストレージ層はHDFSでしたが、Hadoop基盤自体がパブリッククラウドで利用されるようになった結果、S3、ADSL、GCSといったオブジェクトストレージを中心に利用するようになりました(HDFSの場合は常時稼動が必要になり割高になるので)。
また、データを貯めていたストレージ層とワークロードを実行するコンピュート層が分離しやすい環境が整ってきた結果、コンピュート層を柔軟にスケール出来る環境としてコンテナの活用が期待されています。
そこで、ワークロードの中心的なSparkとFlinkは、YARN以外にもKubernetesでアプリを実行できるようになりました5。
一方、Kubernetesのリソーススケジューラは、上記のような柔軟なリソーススケジューリングには対応できないので、そこを補う形でBigDataやMLワークロードに特化したリソーススケジューラとしてYuniKornが出てきました。
ただ、Kubernetesとしてバッチのワークロードについて何もしていないわけではなく、 Batch Working Group として議論・サポートを進めています6。
どこが使ってるのか?
Hadoopといえば、ClouderaですがClouderaのパブリッククラウドサービスのCDP Public CloudのCloudera Data Engineering(CDE)というサービスにYuniKornが利用されています(AWSとAzureで使えるみたいです)。
また、Cloudera以外にもAlibaba、Apple、Lyft、Visa、Zillowで使っているようです。
そして、10月にあったYuniKorn MeetupではPinterestがスケジューラの性能評価について話していて、YARNからKubernetes(YuniKorn)への移行を検討しているようです7。
リリース状況
YuniKorn自体は、今年の5月(2022/5/6)にGAしています!
現状の最新は 2022/9/8 にリリースされた v1.1.0 となっています。
また、Roadmapによると、年明け1月には、v1.2.0がリリース予定のようです。
YuniKornの特徴
YuniKornの主な機能は以下の通りです。
アプリを考慮したスケジューリング
KubernetesデフォルトのPod単位のスケジューリングとは異なり、ユーザー、アプリ、キューを認識して、リソースの状況や順序などの要素を考慮しながらスケジューリングを行います。
Kubernetesでは、PodをSubmitする際にPodがNamespaceのクォータに収まるように強制し、収まらない場合には、Podは拒否されます。その為、クライアント側で再試行出来るよう複雑な実装が必要になります。
一方、YuniKornは、Kubernetesのクォータとは異なり、SubmitされたたPodは常に受け入れられます。
つまり、YuniKornはキューに入ったPodのリソースを消費したクォータとしてカウントせずに、そのPodをキューにいれます。YuniKornがPodをスケジュールしようとすると、スケジューリング時にPodが割り当てられたキューに設定されたクォータに収まるかどうかチェックします。その時にPodがクォータに収まらない場合、Podはスキップされてリソース消費にカウントされません。これは、Podのスケジュール試行に成功するまでは、YuniKornクォータシステムでPodはリソースを消費していないことを意味しています。
階層型のリソースキュー
クラスタリソースを階層型にキューで管理します。また、キューの最小と最大容量を設定出来ます。階層ごとにリソースを制御出来るので、マルチテナント利用の場合に柔軟な対応が可能になります。
そして、リソースキューの状況はYuniKornのUIでモニタリング出来ます(クラスタリソースの容量、利用率、およびすべてのアプリケーション情報を一元的に表示出来ます)。
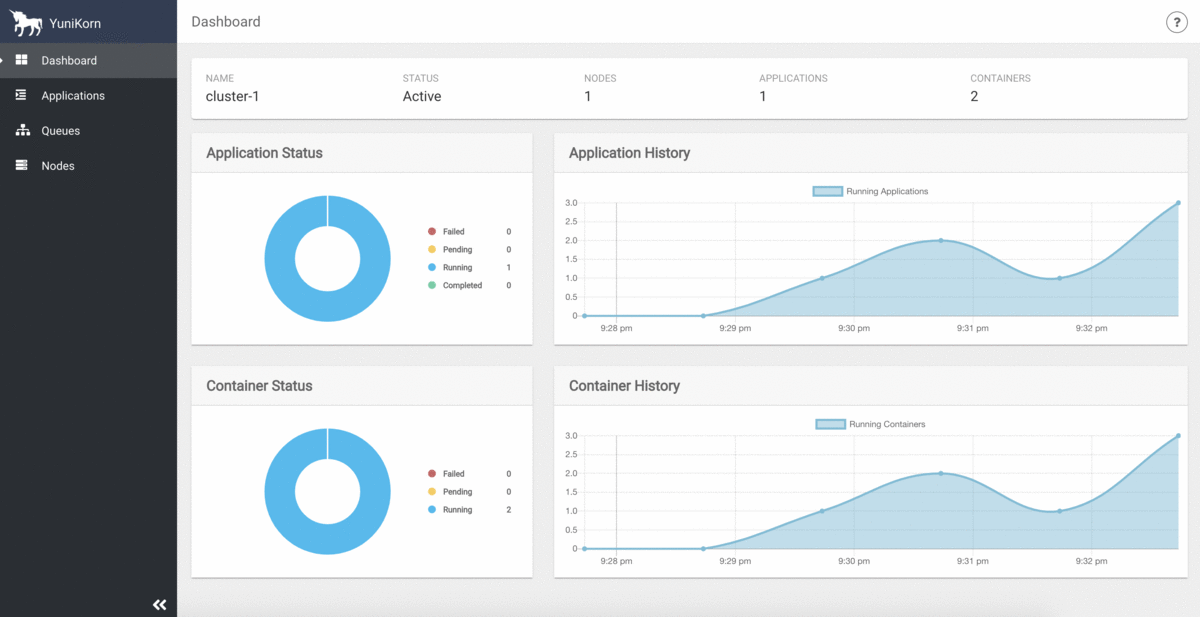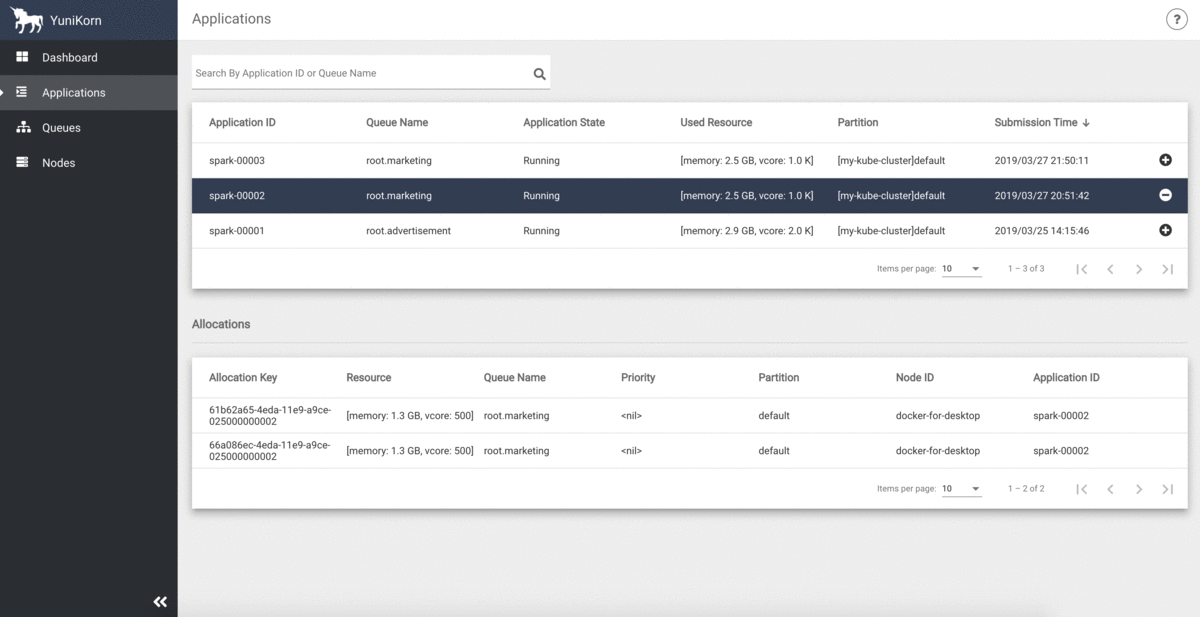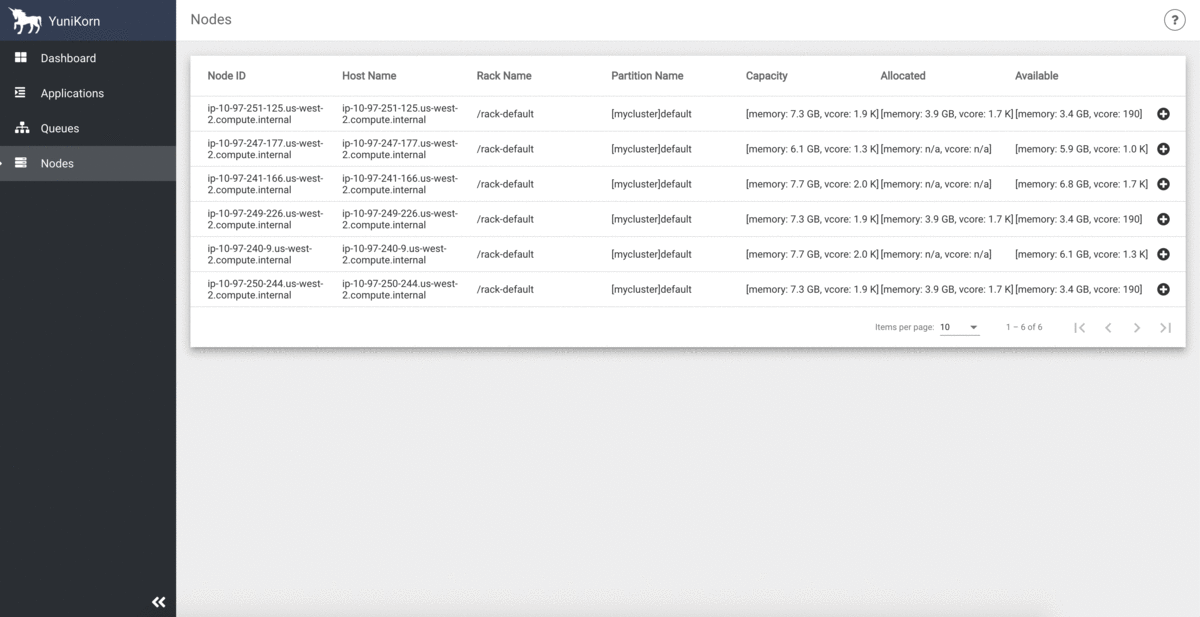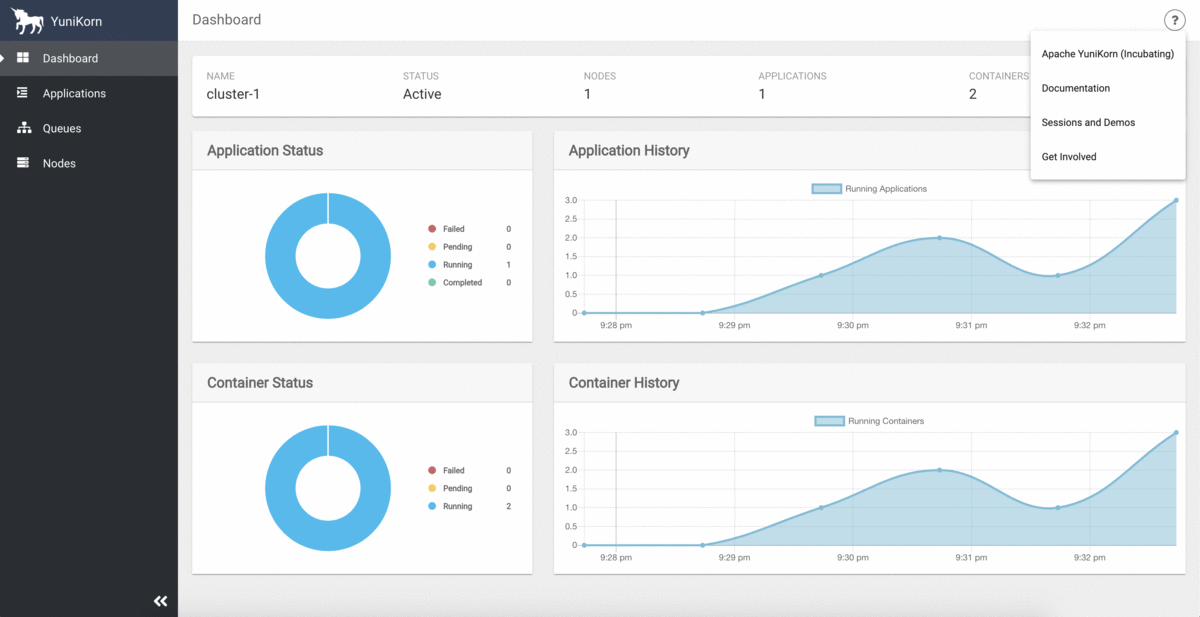
ジョブオーダーとキューイング
アプリは作業キューに格納して、どのアプリが最初にリソースを取得できるのかは、以下のポリシーに応じて決定します。
現状設定可能なポリシーは、以下の3つ。
FIFO: そのまま。先入れ先出し。Fair: アプリケーションの使用量に応じて公平にリソースを配分。StateAware: 実行中または受け入れ状態のアプリは1つに制限される。
StateAware が分かりにくいので補足します。
Sparkアプリを例にとると想像しやすいです。Sparkアプリは、アプリ全体の調整役となるDriverと、Driverが割り当てた細かいタスクを実行する複数のExecuterに分かれて実行していきます。
例えば、あるキュー(app-queue-1)にapp1→app2の順にSparkアプリをsubmitしたときは以下の様に実行されます。

さらに、キューの最大容量を設定した場合、ジョブやタスクはリソースキューに適切にキューイングされて、残りの容量が十分でない場合は、いくつかのリソースが開放されるまで待機させることが出来ます。
リソースの公平性
マルチテナント環境で、多くのユーザーがクラスタリソースを共有します。テナントがリソースを競合させ、飢餓状態(starving)を避けるために、アプリケーションに割り当てるリソースの重みや優先度を設定出来るようになっています。
リソース予約
YuniKornは未解決のリクエストに対して自動的に予約します。Podが割り当てられなかった場合、YuniKornは適切なNodeにPodを予約しようとして、(他のNodeを試す前に)予約されたNodeにPodを仮で割り当てます。
この仕組みにより、後からSubmitされたより小さくてこだわりのないPodによってこのPodが飢餓状態になる事を回避出来ます。
高いスループット
スループットは、スケジューラの性能を測る重要な基準です。スループットが悪いとアプリケーションはスケジュール待ちで時間を浪費し、サービスのSLAに影響します。クラスタが大きくなるほど高いスループットが要求されます。
Kubemarkを用いて、YuniKornとKubernetesのデフォルトのスケジューラに比べた結果、YuniKornが2倍から4倍のスループットを出したようです。
詳細は以下を参照ください。
YuniKornのアーキテクチャ
YuniKornは、カスタムKubernetesスケジューラとしてデプロイ出来るようになっています。
これは異なるshim層を追加して、Apache Hadoop YARNやその他のシステムを含む異なるリソースマネージャの実装に対応する事が可能になっています。
しかし、独自実装を盛り込んだ結果、Kubernetesのアップデートに追従するのが大変でしたが、YuniKorn v1.0.0からKubernetes v1.19以降に追加されたScheduling Frameworkで導入された拡張ポイント(PreFilter、Filter、PostBindの3つ)を実装したプラグインとして利用できるようになりました8。
下図は、YuniKornのScheduler Pluginを利用しない場合のハイレベルなアーキテクチャです。
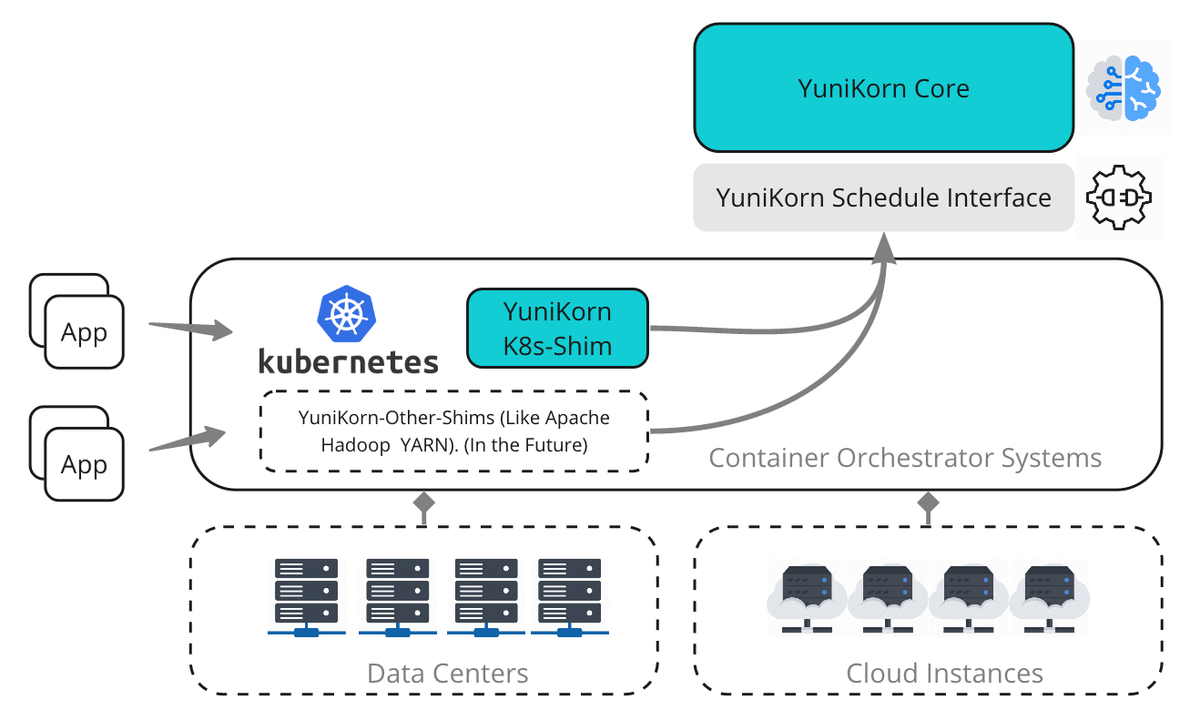
コンポーネント
Scheduler Core
※図中のYuniKorn Coreの事
Scheduler Coreは、すべてのスケジューリングアルゴリズムをカプセル化して、下位のリソース管理プラットフォーム(YARN/Kubernetesなど)からリソースを収集し、コンテナの割り当て要求を担当します。
各リクエストに対して最適な場所はどこかを判断し、リソース管理プラットフォームにレスポンスの割り当てを下位のプラットフォームに依存しないようにすべての通信はScheduler Interfaceを利用します。
詳しくはScheduler Coreの設計を参照ください。
Scheduler Interface
※図中のYuniKorn Scheduler Interfaceの事
リソース管理プラットフォーム(YARN/Kubernetesなど)がgRPCやプログラミング言語バインディングのようなAPIを介して会話する抽象レイヤ
Kubernetes Shim
※図中のYuniKorn K8s-Shimの事
Kubernetes ShimはKubernetesとの対話を担当し、Kubernetesのクラスタリソースや、Scheduler Interface経由のリソースリクエストをScheduler Coreに送ります。 そしてスケジューラが決定すると、Podを特定のNodeに結合する役割を担っています。ShimとScheduler Core間の通信はすべてScheduler Interfaceを介して行われます。
詳しくは、Kubernetes Shimの設計を参照ください。
対応しているワークロードについて
YuniKornが対応しているワークロードは以下の通り
最新の状況は?
10月にあったApache YuniKorn Meetupがあったようでその録画とスライドがありました(ありがたや)。
内容はざっくり以下の通り。
次のバージョン予定されている主な機能
来年1月にリリース予定の v1.2ではで予定しているのは以下だそうです。
- Kubernetes v1.21以降をサポート
- 1キューあたりの最大実行アプリの制限機能の追加
- ユーザーやグループでのクォータの機能について
- 開始ユーザ検索や利用状況の把握するための実装を開始
- 設計が最終段階
- 詳細は デザインドキュメント を参照ください。
今後の方向性について
また、今後の方向性として以下を挙げてました。
- 優先度のサポートについては、最終デザインがペンディング
- Preemptionのサポート
- 一旦、YuniKorn v1.1の古いコードは削除してデザインからやり直し
- フェデレーション
- Kubernetesの制限で1クラスタあたりのノード数に上限あるので、クラスタ跨ぎでクォータ管理を出来るようにするとの事
どうやって使うのか?
ボリュームでかくなったので分けます😇
ひとまず以下が参考になります。
さいごに
いかがだったでしょうか。
KubernetesでBigDataやMLでのワークロードの実行で今後も要チェックなYuniKornの紹介でした。
概要な話が多かったのでより詳細な話は別途、改めてまとめてみます。
以上、 Distributed computing Advent Calendar 2022 の5日目の記事でした。
補足:参考情報
- 公式情報
- ClouderaのBlog
- 過去のイベント(MeetupやApacheCon、KubeConなど)のスライドやセッション動画
- 実は、Distributed computing Advent Calendar 2021 の20日目に書くはずだったネタ…。↩
- The Apache Software Foundation Announces Apache® YuniKorn™ as a Top-Level Project - The Apache Software Foundation Blog↩
-
Hadoopについては以下を参考にしてください。
- Hadoopはどのように動くのか ─並列・分散システム技術から読み解くHadoop処理系の設計と実装:連載|gihyo.jp
- 分散処理技術「Hadoop」とは:NTTデータのHadoopソリューション↩ - 詳しくはこちら。 YuniKorn: a universal resources scheduler - Cloudera Blog↩
-
Running Spark on Kubernetes | Apache Spark
Native Kubernetes | Apache Flink↩ -
ワーキンググループのMTGはYoutubeで公開されています。
https://www.youtube.com/playlist?list=PL69nYSiGNLP05eEikq0j8PcSehEdM4mj7&jct=s4irZjLuvQ2WrUYAGxyRYjs3a2aysg↩ -
スライドはこちら
面白かったのは、500ノードクラスタ、24K Podを同時実行した際に、Spark Operatorが1つではOperatorがボトルネックになったので5つにしたそうです。Operatorが詰まるとかあるのか。規模が違う…。↩ - 詳しくは K8s Scheduler Plugin | Apache YuniKorn を参照。↩
Production-ReadyなK8s(RKE2)クラスタを構築する際のあれこれ
この記事は MicroAd Advent Calendar 2022 の4日目の記事です。
- 前提
- ここで触れないこと
- RKE2って?
- Kubernetesのコンポーネント
- RKE2のアーキテクチャ
- RKE2の制限事項・必要条件
- RKE2 ServerとAgent Nodeの構成をどうするか
- RKE2の設定ポイント
- HAクラスタの構築の流れ
- Tips1:LBの構築ポイント
- Tips2:1台目の設定のserverをコメントアウトしてrke2-serverサービスを再起動する理由
- RKE2(Kubernetes)のアップグレード
- さいごに
- おまけ
- Tips: Rancher CLI
- Tips2: TerraformのRancher2 Provider
本番でUnmanagedなKubernetesクラスタを構築しようとした際にどうやって構築するか悩みますよね。
今回はKubernetesのディストリビューションのRKE2を用いて書いていきます。