この記事は Distributed computing Advent Calendar 2022 の5日目の記事です1。
qiita.com
今回は、今年の5月にApache Software Foundation (ASF)のTop-Level Project (TLP)2になった Apache YuniKorn について紹介します。
yunikorn.apache.org
YuniKornの概要
YuniKornは、YARNで要求されていたワークロードに関するリソーススケジューリングをKubernetesで利用できるよう作成したようです。
YARN(Yet Another Resource Negotiator)とは、Hadoopクラスタ内のジョブのスケジュールやリソース管理する基盤です。
YARN自体に馴染みのない方は以下を見るとYuniKornも理解しやすいです。
YARNの概要とFAIRスケジューラについてはこちら。
www.slideshare.net
Capacityスケジューラについてはこちら。
blog.cloudera.com
また、Hadoop3エコシステムはだいたいJava(一部C++など)で実装されていますが、YuniKornはgolangで実装されています。
YuniKornの由来と読み方
YuniKornの名前の由来は "Y"をYARN(フロントエンドのyarnじゃないよ)、"K"をKubernetes、"Uni"をUnifiedから取っているそうです。
また、発音は[‘ju:nikɔ:n]となり、ロゴにもなっているUnicornと同じです4。
なぜYuniKornが必要なのか?
BigDataやMLでのワークロードは、大量のデータを処理しなければならないので、レイテンシよりもスループットが非常に大事です。
また、この手のワークロードはマルチテナントで利用されることが多く、リソーススケジューリングにする要求は複雑になりがちです。
例えば、以下のような事が普通に求められ、これまで、YARNにて対応してきました(YARNスゴイヨ)。
- 大事なバッチにはクラスタの半分のリソースを優先して割り当てる
- 部門Aのアドホックなワークロードにはクラスタリソースの10%までを割り当てる
- ただし、バッチなど優先したいワークロードがなくヒマしているなら、10%を超えて使ってもOK
- とはいえ、メインのバッチが始まったらワークロードをプリエンプティブする
- さらに、部門Aのリソースのうち、半分はBさんが優先して使ってOK
そして、これまでHadoopエコシステムのストレージ層はHDFSでしたが、Hadoop基盤自体がパブリッククラウドで利用されるようになった結果、S3、ADSL、GCSといったオブジェクトストレージを中心に利用するようになりました(HDFSの場合は常時稼動が必要になり割高になるので)。
また、データを貯めていたストレージ層とワークロードを実行するコンピュート層が分離しやすい環境が整ってきた結果、コンピュート層を柔軟にスケール出来る環境としてコンテナの活用が期待されています。
そこで、ワークロードの中心的なSparkとFlinkは、YARN以外にもKubernetesでアプリを実行できるようになりました5。
一方、Kubernetesのリソーススケジューラは、上記のような柔軟なリソーススケジューリングには対応できないので、そこを補う形でBigDataやMLワークロードに特化したリソーススケジューラとしてYuniKornが出てきました。
ただ、Kubernetesとしてバッチのワークロードについて何もしていないわけではなく、 Batch Working Group として議論・サポートを進めています6。
どこが使ってるのか?
Hadoopといえば、ClouderaですがClouderaのパブリッククラウドサービスのCDP Public CloudのCloudera Data Engineering(CDE)というサービスにYuniKornが利用されています(AWSとAzureで使えるみたいです)。
また、Cloudera以外にもAlibaba、Apple、Lyft、Visa、Zillowで使っているようです。
そして、10月にあったYuniKorn MeetupではPinterestがスケジューラの性能評価について話していて、YARNからKubernetes(YuniKorn)への移行を検討しているようです7。
リリース状況
YuniKorn自体は、今年の5月(2022/5/6)にGAしています!
現状の最新は 2022/9/8 にリリースされた v1.1.0 となっています。
また、Roadmapによると、年明け1月には、v1.2.0がリリース予定のようです。
YuniKornの特徴
YuniKornの主な機能は以下の通りです。
アプリを考慮したスケジューリング
KubernetesデフォルトのPod単位のスケジューリングとは異なり、ユーザー、アプリ、キューを認識して、リソースの状況や順序などの要素を考慮しながらスケジューリングを行います。
Kubernetesでは、PodをSubmitする際にPodがNamespaceのクォータに収まるように強制し、収まらない場合には、Podは拒否されます。その為、クライアント側で再試行出来るよう複雑な実装が必要になります。
一方、YuniKornは、Kubernetesのクォータとは異なり、SubmitされたたPodは常に受け入れられます。
つまり、YuniKornはキューに入ったPodのリソースを消費したクォータとしてカウントせずに、そのPodをキューにいれます。YuniKornがPodをスケジュールしようとすると、スケジューリング時にPodが割り当てられたキューに設定されたクォータに収まるかどうかチェックします。その時にPodがクォータに収まらない場合、Podはスキップされてリソース消費にカウントされません。これは、Podのスケジュール試行に成功するまでは、YuniKornクォータシステムでPodはリソースを消費していないことを意味しています。
階層型のリソースキュー
クラスタリソースを階層型にキューで管理します。また、キューの最小と最大容量を設定出来ます。階層ごとにリソースを制御出来るので、マルチテナント利用の場合に柔軟な対応が可能になります。
そして、リソースキューの状況はYuniKornのUIでモニタリング出来ます(クラスタリソースの容量、利用率、およびすべてのアプリケーション情報を一元的に表示出来ます)。
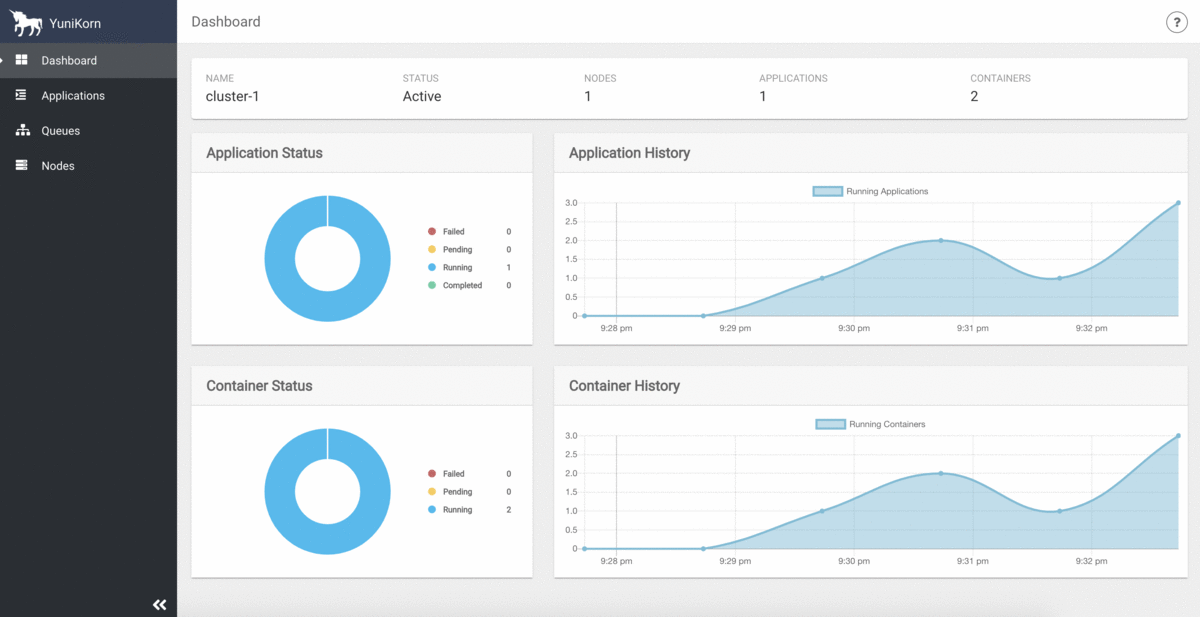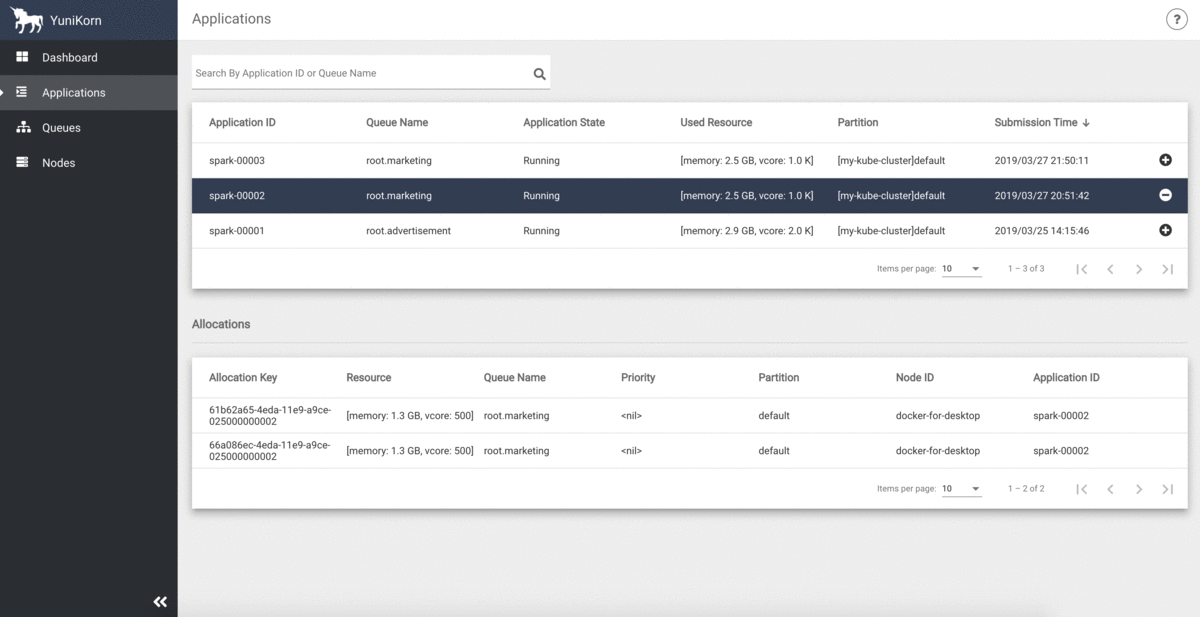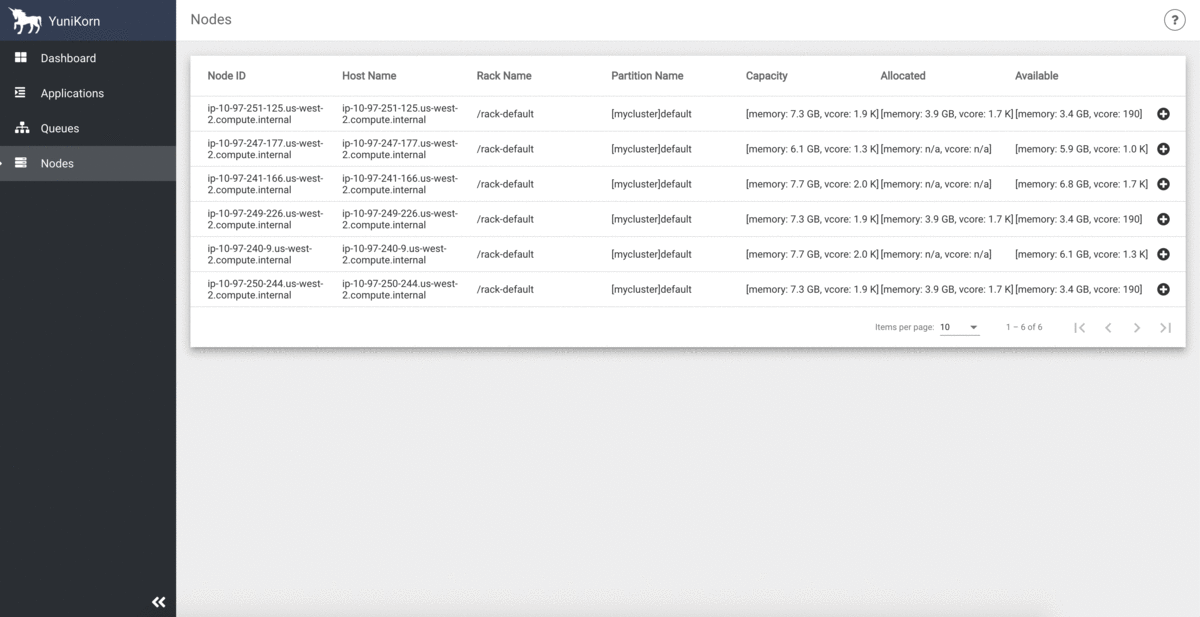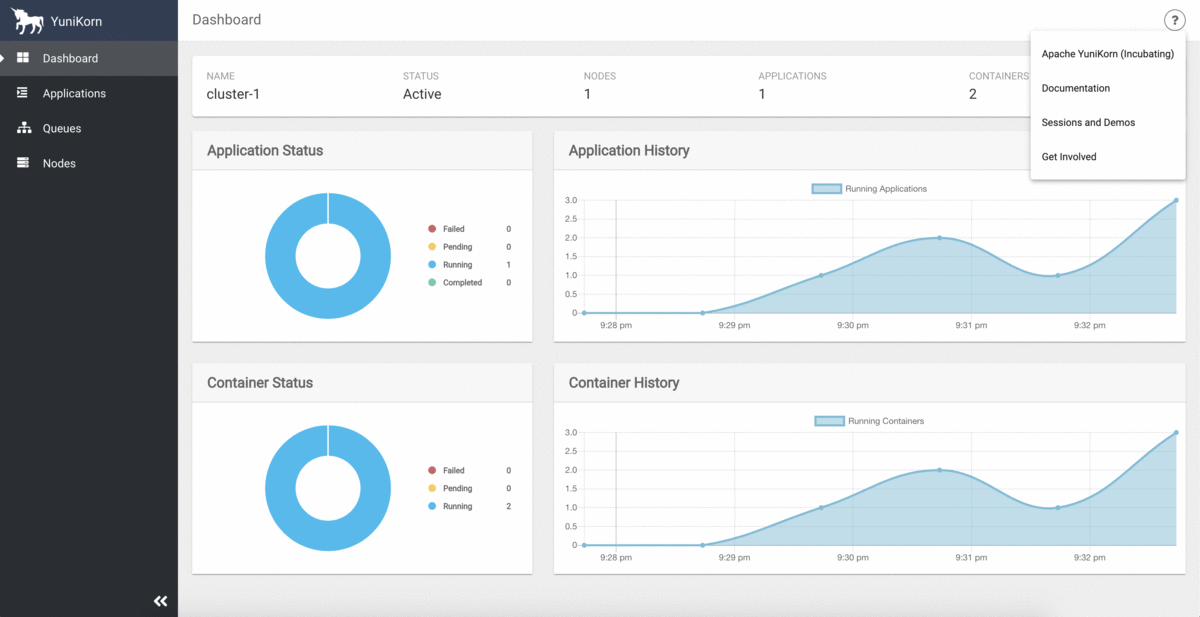 YuniKorn UI
出典: Get Started | Apache YuniKorn より
YuniKorn UI
出典: Get Started | Apache YuniKorn より
ジョブオーダーとキューイング
アプリは作業キューに格納して、どのアプリが最初にリソースを取得できるのかは、以下のポリシーに応じて決定します。
現状設定可能なポリシーは、以下の3つ。
FIFO : そのまま。先入れ先出し。Fair : アプリケーションの使用量に応じて公平にリソースを配分。StateAware : 実行中または受け入れ状態のアプリは1つに制限される。
StateAware が分かりにくいので補足します。
Sparkアプリを例にとると想像しやすいです。Sparkアプリは、アプリ全体の調整役となるDriverと、Driverが割り当てた細かいタスクを実行する複数のExecuterに分かれて実行していきます。
例えば、あるキュー(app-queue-1)にapp1→app2の順にSparkアプリをsubmitしたときは以下の様に実行されます。
 StateAwareの説明
StateAwareの説明
さらに、キューの最大容量を設定した場合、ジョブやタスクはリソースキューに適切にキューイングされて、残りの容量が十分でない場合は、いくつかのリソースが開放されるまで待機させることが出来ます。
リソースの公平性
マルチテナント環境で、多くのユーザーがクラスタリソースを共有します。テナントがリソースを競合させ、飢餓状態(starving)を避けるために、アプリケーションに割り当てるリソースの重みや優先度を設定出来るようになっています。
リソース予約
YuniKornは未解決のリクエストに対して自動的に予約します。Podが割り当てられなかった場合、YuniKornは適切なNodeにPodを予約しようとして、(他のNodeを試す前に)予約されたNodeにPodを仮で割り当てます。
この仕組みにより、後からSubmitされたより小さくてこだわりのないPodによってこのPodが飢餓状態になる事を回避出来ます。
スループットは、スケジューラの性能を測る重要な基準です。スループットが悪いとアプリケーションはスケジュール待ちで時間を浪費し、サービスのSLAに影響します。クラスタが大きくなるほど高いスループットが要求されます。
Kubemarkを用いて、YuniKornとKubernetesのデフォルトのスケジューラに比べた結果、YuniKornが2倍から4倍のスループットを出したようです。
詳細は以下を参照ください。
yunikorn.apache.org
YuniKornは、カスタムKubernetesスケジューラとしてデプロイ出来るようになっています。
これは異なるshim層を追加して、Apache Hadoop YARNやその他のシステムを含む異なるリソースマネージャの実装に対応する事が可能になっています。
しかし、独自実装を盛り込んだ結果、Kubernetesのアップデートに追従するのが大変でしたが、YuniKorn v1.0.0からKubernetes v1.19以降に追加されたScheduling Frameworkで導入された拡張ポイント(PreFilter、Filter、PostBindの3つ)を実装したプラグインとして利用できるようになりました8。
下図は、YuniKornのScheduler Pluginを利用しない場合のハイレベルなアーキテクチャです。
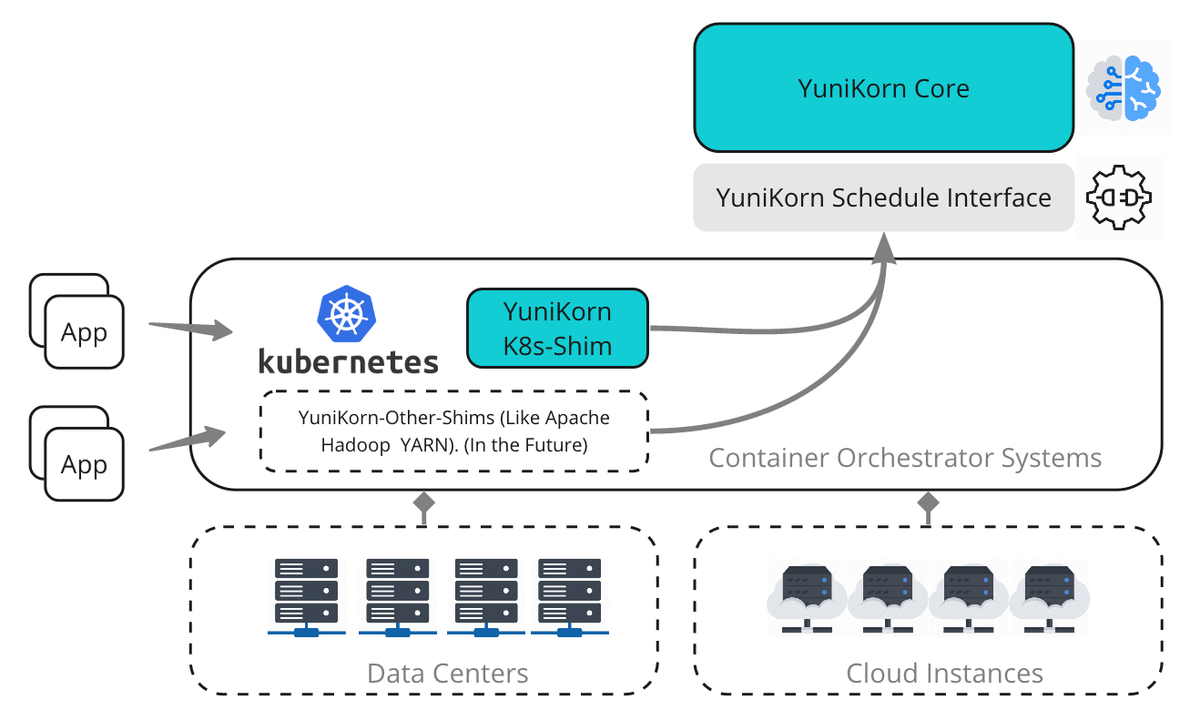 YuniKornのアーキテクチャ図
出典: Architecture | Apache YuniKorn より
YuniKornのアーキテクチャ図
出典: Architecture | Apache YuniKorn より
Scheduler Core
※図中のYuniKorn Coreの事
Scheduler Coreは、すべてのスケジューリングアルゴリズムをカプセル化して、下位のリソース管理プラットフォーム(YARN/Kubernetesなど)からリソースを収集し、コンテナの割り当て要求を担当します。
各リクエストに対して最適な場所はどこかを判断し、リソース管理プラットフォームにレスポンスの割り当てを下位のプラットフォームに依存しないようにすべての通信はScheduler Interfaceを利用します。
詳しくはScheduler Coreの設計を参照ください。
Scheduler Interface
※図中のYuniKorn Scheduler Interfaceの事
リソース管理プラットフォーム(YARN/Kubernetesなど)がgRPCやプログラミング言語バインディングのようなAPIを介して会話する抽象レイヤ
※図中のYuniKorn K8s-Shimの事
Kubernetes ShimはKubernetesとの対話を担当し、Kubernetesのクラスタリソースや、Scheduler Interface経由のリソースリクエストをScheduler Coreに送ります。 そしてスケジューラが決定すると、Podを特定のNodeに結合する役割を担っています。ShimとScheduler Core間の通信はすべてScheduler Interfaceを介して行われます。
詳しくは、Kubernetes Shimの設計を参照ください。
対応しているワークロードについて
YuniKornが対応しているワークロードは以下の通り
最新の状況は?
10月にあったApache YuniKorn Meetupがあったようでその録画とスライドがありました(ありがたや)。
youtu.be
内容はざっくり以下の通り。
次のバージョン予定されている主な機能
来年1月にリリース予定の v1.2ではで予定しているのは以下だそうです。
- Kubernetes v1.21以降をサポート
- 1キューあたりの最大実行アプリの制限機能の追加
- ユーザーやグループでのクォータの機能について
- 開始ユーザ検索や利用状況の把握するための実装を開始
- 設計が最終段階
今後の方向性について
また、今後の方向性として以下を挙げてました。
- 優先度のサポートについては、最終デザインがペンディング
- Preemptionのサポート
- 一旦、YuniKorn v1.1の古いコードは削除してデザインからやり直し
- フェデレーション
どうやって使うのか?
ボリュームでかくなったので分けます😇
ひとまず以下が参考になります。
さいごに
いかがだったでしょうか。
KubernetesでBigDataやMLでのワークロードの実行で今後も要チェックなYuniKornの紹介でした。
概要な話が多かったのでより詳細な話は別途、改めてまとめてみます。
以上、 Distributed computing Advent Calendar 2022 の5日目の記事でした。
補足:参考情報
- 公式情報
- ClouderaのBlog
- 過去のイベント(MeetupやApacheCon、KubeConなど)のスライドやセッション動画