この記事は MicroAd Advent Calendar 2023 と Distributed computing (Apache Spark, Hadoop, Kafka, ...) Advent Calendar 2023 の1日目の記事です。
今年もアドカレの季節がやってきました🎄
今回は、ここ数年でデータ界隈で盛り上がっているOpen Table FormatのIcebergテーブルについて書いていきます。 Hiveテーブルとの比較とか、Icebergテーブルの特徴(Time Travel や Rollback、Hidden Partitioning、Full Schema Evolution等)については、あっちこっちで大分こすられてます。
そこで、Icebergテーブルの特徴がなぜ実現できているのかについて知るために、内部構造がどうなっているかを掘り下げていきます。 また、内部構造を知ることでIcebergテーブルを利用する際の運用面についてもイメージしやすくなってくると思います。
では、始めていきます。
(´-`).。oO(ソースコードまでは掘り下げできなかったので、ソースコードコードリーディングとかしたいですね。私はほぼ読めませんけど。)
はじめに
Icebergテーブルのアーキテクチャは、大きく3つに構成されます。

- カタログ
- メタデータ層
- データ層
そこで、今回は、データ層→メタデータ層→カタログの順に、下から上に説明していきます。
Icebergテーブル:データ層

実際のデータを格納する層。
主にデータファイル自体で構成され、クエリしたユーザに結果を返すために必要なデータを提供します。
ただし、後述のメタデータ層の構造体が結果を返す例外もあります(例えば、ある列の最大値など)。
また、データ層は、分散ファイルシステム(HDFS)や、オブジェクトストレージ(S3)に対応してます。 実際には、以下の3つで構成されています。
- データファイル
- 削除ファイル
- Puffinファイル
では、この3つについて説明してきます。
データ層(データファイル)
データそのものを格納しています。
Icebergtテーブルは、ファイル形式にとらわれず、列指向で参照する際に最適な読み込みパフォーマンス重視のParquet1・ORC2、行指向でストリーミングなどの書き込みパフォーマンス重視のAvro3に対応してます。そのため、テーブルのワークロードに合わせたファイル形式4を選択できます。
この辺はHive5と同じですが、Icebergではテーブル中に複数のファイル形式を持つことも可能です。 つまり、SparkなどストリーミングでデータレイクにSinkする際はWrite重視のAvroを用い、テーブルをクエリする際にパフォーマンス出るようにRead重視のParquetに「後から」変換すると言った戦略を取ることが可能です。
データ層(削除ファイル)
削除ファイルは、テーブル内のどのレコードが削除されたかを追跡する際に利用します。
削除や更新の際は、Copy-On-Write(CoW)と、Merge-On-Read(MoR)の2種類の戦略があります。
前者 Copy-On-Writeは、削除・更新操作の際、古いファイルをコピーして、変更を反映した新しいファイルを用意します。この場合、読込み時は速いが、書き込みに時間がかかります。
一方、後者 Merge-On-Readは、新しいファイルに削除・更新といった変更点だけを書き込んだ削除ファイルを用意します。
そして読み込む際に、削除ファイルとデータファイルをマージして結果を返します。これは書き込みは速いが、読み込みが遅くなります。
さらに削除ファイルの戦略にも位置削除と均等削除と2種類あるのですが、話すと長くなるので詳細についてはまた今度6。
注意点として、Merge-On-Readを取ったとしても、後から、削除ファイルをマージして新しいデータファイルを作成するといった対応は可能です。
データ層(Puffinファイル)
最後にPuffinファイル。
データファイルやメタデータファイルに格納される統計情報よりも更に幅広いクエリのパフォーマンスを向上させるデータテーブル内のデータに関する統計情報とインデックスを格納しています。
これには、Apache DataSketches7というライブラリのTheta sketchを用いてファイルを作成しているそうです。 細かい話は以下の記事が参考になります。
Icebergテーブル:メタデータ層

ここにはIcebergテーブルのすべてのメタデータファイルを含んでいます。
これらは、ツリー構造になっていて、全ての操作がメタデータとデータファイルで追跡されています。 このツリーは、以下の3つで構成されています。
これらはIcebergテーブルの特徴的な機能である、Time Travel・Rollback、Hidden Partitioning、Full Schema Evolution等には不可欠なものとなります。
ではこれも下から順に説明していきます。
メタデータ層(マニフェストファイル)
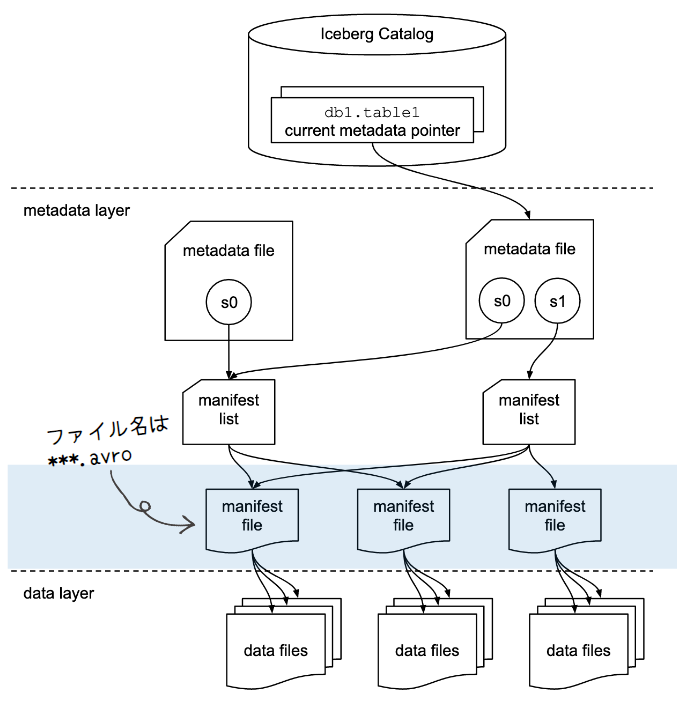
ファイル名は、 *****.avroとなります。
マニフェストファイルは、データ層内のファイル(データファイル、削除ファイル、Puffinファイル)の追跡と、各ファイルに関する追加の詳細や統計情報を保持します。
Hiveテーブルと決定的な違いとして、Icebergテーブルはファイルレベルでテーブルにどのようなデータがあるかを追跡しています。
また、1つのマニフェストファイルには、データファイルまたは削除ファイルのみが含まれます。
他にも各マニフェストファイルには、パーティションのどこに紐づいているか、レコード数、カラムの上限と下限値などの情報が含まれています。 その結果、データファイルを開く操作を減らせるのでクエリパフォーマンスの向上が見込めます。

メタデータ層(マニフェストリスト)
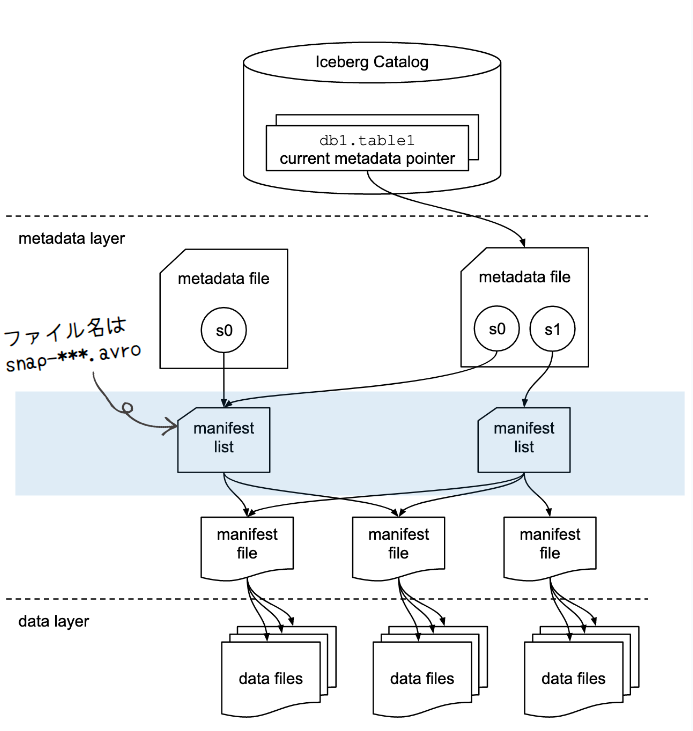
ファイル名はsnap-***.avroとなります。 マニフェストリストは、その名の通り、マニフェストファイルのリストです。
マニフェストリストには、スナップショット(Icebergテーブルのある時点でのテーブルの状態)を構成する各マニフェストファイルに関する情報があります。 なので、マニフェストリストは、スナップショットのリストと考えるとイメージしやすくなります。
マニフェストリストが持っている各マニフェストファイルに関する情報には、代表的なものとして、以下が含まれます。
これらは、テーブル・スキャンを計画する際にスナップショット内のすべてのマニフェストのスキャンを回避するために使用できる要約メタデータが含まれます。 マニフェストのリストは常に新しいスナップショットを生成するために変更されるため、スナップショットをコミットしようとするたびに新しいマニフェストリストが書き込まれます。

メタデータ層(メタデータファイル)
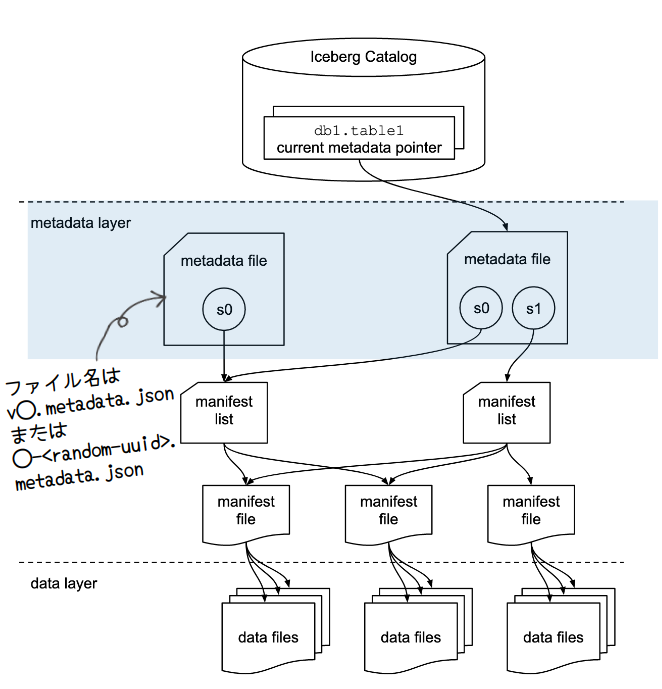
ファイル名は、 v◯.metadata.json または、◯-<random-uuid>.metadata.json となります(◯は数字)。これはカタログ(次で説明)の実装により決まります。
メタデータファイルには、テーブルに関するメタデータを格納し、以下の情報が含まれています。
- テーブルのスキーマ情報
- パーティションの仕様などのパーティションに関連する情報
- パーティション情報や履歴
- タイムスタンとスナップショットIDのペア
- 有効なスナップショットのリスト
- スナップショットのサマリ、ファイルの数やトータルレコード数など
- テーブルのプロパティ(例えば、オーナーは誰かとか)
他にもテーブルのUUIDやテーブルデータやメタデータを書き込む場所なども含まれています。
メタデータファイルは、Icebergテーブルが変更されるたびに新しいメタデータファイルが作成されます。
また、カタログによりアトミックに最新版のメタデータファイルとして登録されます。
これにより、新しいファイルが書き込み中でも、カタログは書き込みが始まる前の最新のメタデータファイルを指したままなので、中途半端な状態のテーブルを参照することは無いです。その他にも、この仕組みは、複数のエンジンが同時にデータを書き込むと言ったコンカレントな書き込みなどのシナリオにも役に立ちます。
Icebergテーブル:カタログ

最新のメタデータがどこにあるかが保持されています。
その為、カタログの主な要件は、現在のメタデータのポインタを更新するためのアトミックな操作をサポートすることにあります。
また、カタログには色々な実装があります。代表的な実装としては以下の通り。
- S3やHDFSといった分散ストレージ上のテーブルのメタデータフォルダにメタデータファイルのバージョン番号を格納した
version-hint.textを作成して管理する「Hadoopカタログ」 - Hive Metastoreを使ってHiveテーブルのLocationプロパティにメタデータファイルのパスを格納する「Hiveカタログ」
- Gitの概念をテーブルに持ち込んだユニークな実装の「Nessieカタログ8 」
- AWSのサービスとして提供されている「AWS Glueデータカタログ」
- RESTfulなサービスプロバイダをIcebergカタログにした「RESTカタログ」
- ただ、RESTカタログはあくまでI/Fでありバックエンドに別のカタログを指定する必要があります
最後に
いかがだったでしょうか。 内部構造を知ることでIcebergの特徴のしくみや運用面で何が必要になっていくるか見えてたのではないでしょうか。 また、元ネタはあるものの、Specみたりしながら自分なりにまとめてみると色々気づきがあってよかったです。もし勘違い・不足などあれば、こっそり教えてください。
本当は、実際にテーブルを作成してからデータを挿入、削除などの操作をした際にIcebergテーブルがどの様に変化をするかも含める予定だったのですが、長くなったので、Distributed computing Advent Calendar 2023 の違う日に説明しようと思います。また、25日目には、Icebergテーブルのデータ層にS3互換ストレージとしてMinIOではなく、Apache OzoneのHadoop互換のファイルシステム ofs11 を使って環境をつくれないか試行錯誤した記事を書く予定です。お楽しみに?
以上、MicroAd Advent Calendar 2023 と Distributed computing (Apache Spark, Hadoop, Kafka, ...) Advent Calendar 2023 の1日目の記事でした。
さーて、明日、2日目の記事は、、、
MicroAd Advent Calendar 2023 は、棋譜を暗記するツールを作った話。
そして、Distributed computing Advent Calendar 2023 は、引き続きIcebergネタとなっています。
どちらも楽しみですね!
参考
- Iceberg Table Spec
- Puffin file format
- Apache Iceberg: Architectural Insights | Dremio
- Apache Iceberg: The Definitive Guide [Book]
補足
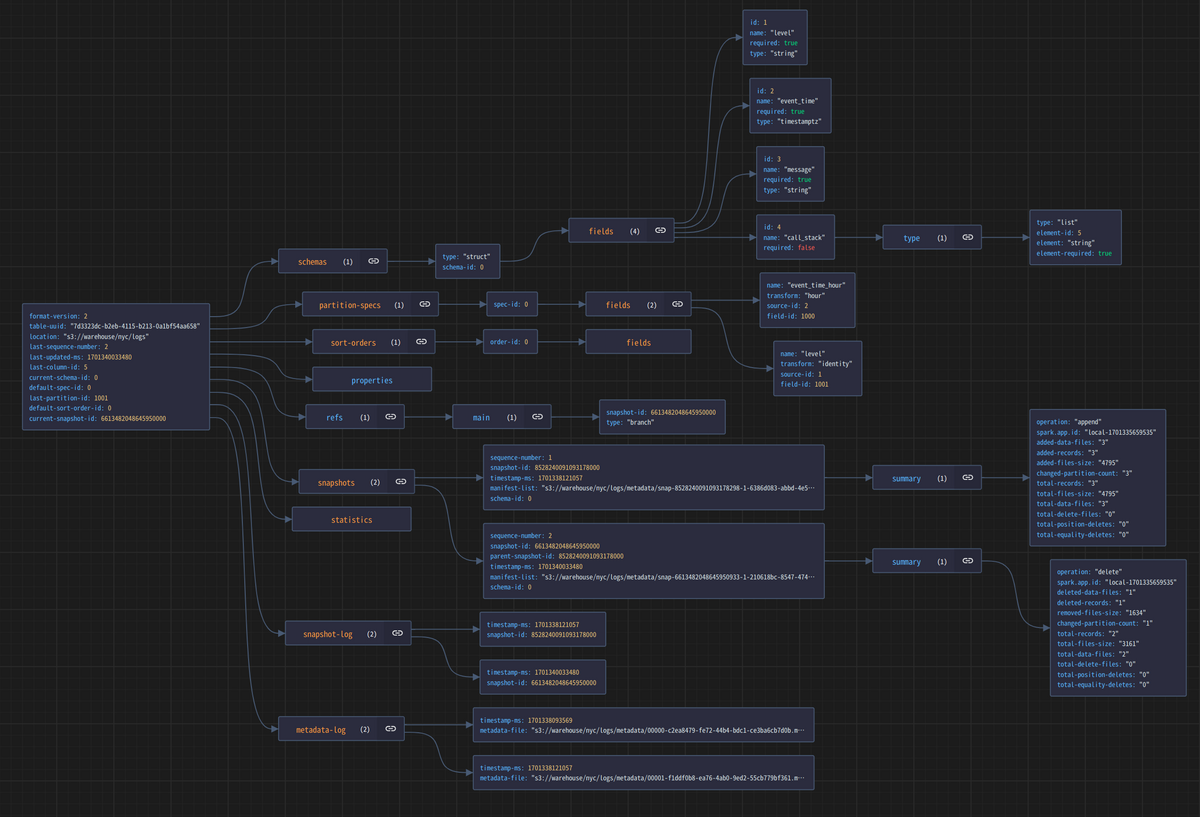
記事中の図で使ったメタデータ層の各ファイルは、以下のSpark + Iceberg Quickstart Imageを使って環境を用意して、「Iceberg - An Introduction to the Iceberg Java API」っていうNotebookで作成したテーブルを使ったものを使用しています。
また、JSONの可視化は、vscodeの拡張 JSON Crack を使っています。
そして、Avroファイルについては、AvroのサイトからDLったJARを使って以下の様にJSONに変更してます。
java -jar avro-tools-1.11.3.jar tojson --pretty $(f) > $(f).json
-
Apache Parquet(ぱーけぃ)
parquet.apache.org↩ -
Apache ORC
orc.apache.org↩ -
Apache Avro
avro.apache.org↩ -
この辺の記事が面白いです。
カラムナフォーマットのきほん 〜データウェアハウスを支える技術〜 - Retty Tech Blog↩ -
Apache Hive
hive.apache.org↩ -
この辺を読むと理解が深まります。
Row-Level Changes on the Lakehouse: Copy-On-Write vs. Merge-On-Read in Apache Iceberg | Dremio↩ - https://datasketches.apache.org/↩
-
Project Nessie
projectnessie.org↩ -
Apache Hudi
hudi.apache.org↩ -
Delta Lake
delta.io↩ - https://ozone.apache.org/docs/1.3.0/interface/ofs.html↩