この記事は MicroAd Advent Calendar 2024 と Distributed computing (Apache Spark, Hadoop, Kafka, ...) Advent Calendar 2023 の25日目の記事です。
12/25は終わってしまっていますが、、25日目の記事です。25日目といったら25日目なんです。
遅れた理由は色々とあるのですが、本題いきましょう1。
今回は、ずっとSpark Structure Streamingで良いんちゃう?って事で横目で見続けてきた、この子。

Flinkについてやっていきます。
Sparkは処理するデータの範囲が決まっているバッチ領域から発展して、常にデータが流れ込んでくるストリーム領域をマイクロバッチって観点で広げていった経緯があります。一方、Flinkはその逆で、ストリームからバッチへ対応領域を広げていった経緯があります。どこの世界もバッチもストリームもすべて対応する明るい未来(?)に向けて切磋琢磨しています。
今回はFlinkの話に触れてから、実際にKubernetesにはRKE2 2 を使ってクラスタをササッと用意してそこにFlinkの環境をいれてサンプル起動してみる流れでハマりどころを補足しながら紹介していきます。 うちはProxyがあってね、、、って方も大丈夫です。
前提(というか今回の環境)
- Ubuntu v22以降
- RKE2 (Kubernetes v1.31)
- Apache Flink v1.20
- Apache Flink Kubernetes Operator v1.10
Flinkの最新情報とv2.0の話
今年のFlinkを振り返り
今年はFlinkの話がてんこ盛りの年でした。
FlinkのカンファレンスなのでFlink贔屓になりがちですが、 Flink Forward 2024 で以下の面白いセッションがありました。
SparkとFlinkの違いについて説明するセッションでとても興味深い内容でした3。
また、登壇者の方が後日、以下の記事で補足しています。
レイテンシ以外にもストリームに特化している点やKafkaをかなり意識した実装になっている分、Spark Structure Streamingでのツラミを考えるとFlinkもありだなぁとしみじみ感じました。。。
また、同じスピーカーの方がConfluentの年次イベントのCurrent 2024にて、Flink SQLで行うイベントタイム処理の話をしていて、こちらのスライドもとても興味深いです。
他にも、FlinkとIcebergは元から関係は深いのですが、Flussっていう、Streaming Lakehouseなんて面白そうなものが出てきました。また、FlussはASFに仲間入りするらしいです。
Fluss: Unified Streaming Storage For Next-Generation Data Analytics
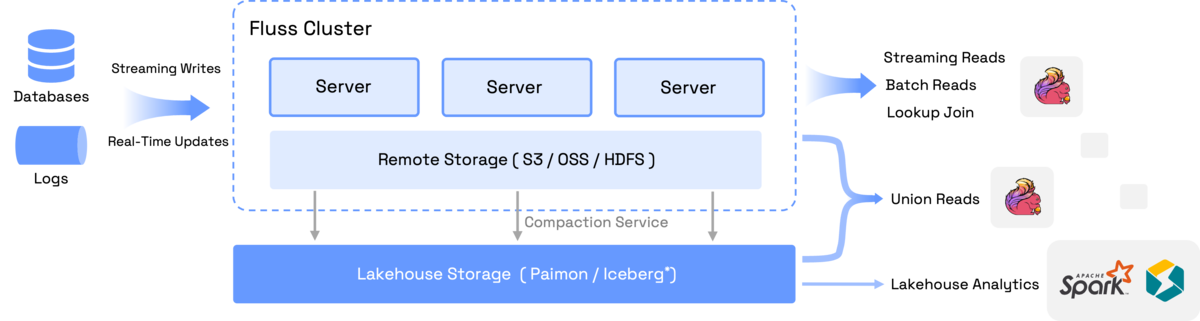
今後の動向が気になります。
また、この記事のVerverica4は、2024年の1月にFlink CDC v3としてApache Software Foundationに寄贈されてます。以下のスライドはFlink CDCのv3に至る変遷が分かりやすいです。 YAMLでCDCの設定を書くってのはシンプルで良い感じですね(Embulkっぽさがある)。
Flink CDCについては、ブログ記事などは以下にまとまってます。
また、詳しい解説は以下の記事が参考になります。
YAMLでCDC出来るなら横展開しやすいのでありがたいですね。
Flink v2.0の話
Apache Flink 1.20 は、今年の8月にリリースされています。 また、以下の通り、Flink 1.0 のリリースから8年が経過し、Flinkはv2.0がプレビュー版として10月に公開されており、2024年末に向けてGA目指しているらしいですが、年越しそうですね。
Breaking Changes
Flink v2.0ではメジャーアップデートに伴う非互換性の変更が結構入っています。
- 削除されるAPI
- 変更されるAPI
- 設定ファイルの変更
- 従来の
flink-conf.yamlを廃止し、新しいYAML標準に準拠した設定ファイルconfig.yamlへ移行 - 非推奨の設定キーも削除
- 従来の
- Stateの互換性
- Checkpoint/Savepointのフォーマットが変更され、1.x系と2.0の間で100%の互換性は保証されない
- 移行用のツールをコミュニティが開発中らしい
- Java 8サポートの終了
- Per-Jobモードの削除
- 従来のPer-Jobクラスターモードが2.0では非推奨
また、新しいAPIに合わせ、コミュニティが下記主要コネクタを優先的に対応中: Kafka、Paimon、JDBC、Elasticsearch 上記以外のコネクタは順次対応予定で、開発に参加するコミッターを募集中だそうです。
なので、Flink v2.0から始める場合は、以下を使うことを意識すると良さそう。
- バッチ処理も含めて Java DataStream API に統一
- Table API/SQLの活用
- カスタムコネクタなどの実装は、新しい Source / Sink V2 を使う
- ユーザー定義のテーブルソースやテーブルシンクを使う場合は、DynamicTableSource、DynamicTableSink を使う
- 旧タイプ定義系クラス(例: TableSchema、TableColumn、Types)は使わずに Schema、Column、DataTypes を使う
ストリーミング機能強化:Disaggregated State Management
他にもストリーミング機能強化として、Disaggregated State Managementが挙がっています。
Flinkは伝統的に計算ノードとローカルディスク上のStateを密結合させて高パフォーマンスを実現してきました。しかし、以下の点で制約があります。
- コンピュートリソースとストレージ容量を独立してスケールできない
- コンテナ環境下で、チェックポイント処理によるCPUやI/O負荷のピークが予測しづらい
- クラウドストレージ(S3, OSSなど)を有効活用したい
- ステートが巨大になった場合のリスケーリングやリカバリ時間が増大
そこで、解決策として、Disaggregated State Management が登場。
その要になるのが、 “ForSDB” (For Streaming DB) です。
- FlinkタスクからStateを切り離し、クラウドストレージ(S3やOSS、HDFSなど)に直接書き込み/読み取りを可能にする仕組み
- ローカルディスクへの依存を低減し、容量制限の問題を解消
- チェックポイント時やリスケール時に巨大な状態をダウンロード・再配置する必要がなくなるため、高速化が期待できる
ただ、クラウドストレージを使う場合の課題として、ストレージの遅延をどう解消するかがポイントになります。
そこについては、以下の取り組みをしているそうです。
- ローカルディスクよりレイテンシが高いDFSを使うとパフォーマンス低下が懸念される
- Async実行モードを導入し、State I/Oと計算を非同期化
- 必要に応じてローカルディスクをキャッシュとして利用できる“Hybrid Cache”を開発
実装状況としては、以下の通り。
- Flinkコミュニティにて複数のFlink Improvement Proposal (FLIP)を策定し、段階的に実装中
- すでにプレビュー版が公開されており、一部機能を試すことが可能
ForStDBについては、以下で詳しく紹介されているのですが、、理解できない点が多くて、誰か教えて🙃
- Enabling Flink's Cloud-Native Future Introducing ForStDB in Fink 2.0
- ForStDBのプレビュー版: https://github.com/ververica/ForSt/releases/tag/v0.1.2-beta
Materialized Table
マテリアライズドテーブルは、クエリとデータ鮮度(FRESHNESS) を定義しておくと、Flink エンジンが自動的にテーブルスキーマを推論し、継続的なデータ更新パイプラインを構築してくれます。
すでに Flink 1.20 で MVP(最小実行可能製品)として導入済みの機能です。Flink 2.0 では、運用面などがさらに強化される見込みです。
また、バッチとストリーミングの処理をシームレスに扱い、SQL のみで継続的なデータ変換を行えるのが大きな特徴です。
Adaptive Batch Execution
論理プランおよび物理プランの動的な最適化が導入される予定です。 さらに、バッチの実行中に得られた実行結果(例:カーディナリティ情報やデータ分布)をもとに、最適化戦略の第1段としては、ブロードキャスト結合とスキュー結合が、動的に最適化されるようです。
Streaming Lakehouse
以下の通り、Flink 2.0 では、Apache Paimon(旧名 Flink Table Store)との連携がさらに緊密化されます
- SQL プランの最適化:Paimon のリッチなマージエンジンを活用し、Flink SQL のプラン最適化を推進
- ルックアップ結合のパフォーマンス向上:バケット情報を活用することで、データ読み込みの効率化が期待できます
- Materialized Table、Adaptive Batch Execution、Speculative Execution など Flink 2.0 の新機能サポート:Paimon と組み合わせることで、レイクハウス全体のリアルタイム更新やバッチ最適化がよりシームレスに行えます
これに加えて、Flussも加われば、カラム形式によるストリーミング保存が可能になるし、今後予定しているKafkaプロトコル互換が進めば、ストリームデータはKafkaからConsumeしてデータレイクにSinkしてバッチでテーブルに取り込んでとかしなくても、直接クエリする世界がまってると思うと最高ですね。
では、触りたくてたまらなくなってくる頃ですので、動かしていきます。
Flinkには公式にKubernetesのOperatorがあるのでそれを使って環境を構築していきます。
Flink Kubernetes Operatorを使うと、FlinkDeploymentリソースをマニフェストで定義してapplyすると、Flink Clusterが起動します。
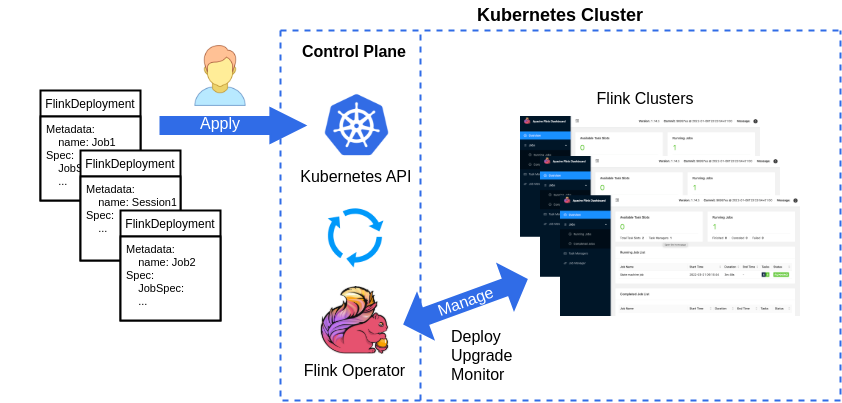
ただ、残念なことにFlink v2.0には対応してないので、GAしている最新のFlink v1.20を対象にします。
RKE2を使ってFlink on Kubernetesを始める
RKE2でKubernetesクラスタの構築
今回はお試しなので、Kubernetes側はHA無視して簡単な構成にします。
Control Planeが1台と、Flink OperatorやFlinkジョブといった実際のワークロードを動かすノード3台の構成とします。
仮にFQDNで以下の構成とします。
# Control Plane yassan-cp01.internal # Node yassan-node01.internal yassan-node02.internal yassan-node03.internal
また、Kubeadmは使わずに、RKE2を使っていきます。RKE2については過去のアドカレで扱ってるのでそっちも是非読んでみてください。
まずは、OSのセットアップまで済んだNodeを4台用意します。Nodeに関する要件は以下を参考にしてください。
Control Plane(RKE2 Server Node)の構築
まずは、Control Planeから構築していきます。
Control PlaneのNodeにて以下を実行してRKE2をインストール。
# curl -x http://proxy.example.com:8080 -sfL https://get.rke2.io | INSTALL_RKE2_CHANNEL="v1.31" INSTALL_RKE2_TYPE="server" sh -
※ Proxy不要な場合は -x http://proxy.example.com:8080 は不要
次にProxyな方は以下を作成5。
tee /etc/default/rke2-server <<EOF
HTTP_PROXY=${HTTP_PROXY}
HTTPS_PROXY=${HTTP_PROXY}
NO_PROXY="${NO_PROXY},.svc,.local"
EOF
次に設定ファイル /etc/rancher/rke2/config.yaml を以下のように作成。
# openssl rand -base64 32 とかでランダム文字列を生成してやる token: SYfnuawdPNXGEqnGPWGIM/WJy3wYV1Pixd2gRwL7hTA= cluster-domain: yassan.local # ホントはよろしく無いけどLBなしに直接つなぐので以下を入れておく tls-san: - yassan-cp01.internal - yassan.local # Network & CNI 関連 cni: cilium
後は、サービス起動して待つだけ。
# systemctl daemon-reload # systemctl enable --now rke2-server.service # journalctl -ef -u rke2-server.service
Node(RKE2 Agent Node)の構築
次に、作成したControl Planeの配下になるNodeを3台とも同じ手順で構築。
各Node で以下を実施して、RKE2をインストール。
# curl -sfL https://get.rke2.io | INSTALL_RKE2_CHANNEL="v1.31" INSTALL_RKE2_TYPE="agent" sh -
Control Planeと同様にProxyな人は以下を実行
tee /etc/default/rke2-agent <<EOF
HTTP_PROXY=${HTTP_PROXY}
HTTPS_PROXY=${HTTP_PROXY}
NO_PROXY="${NO_PROXY},.svc,.local"
EOF
Node用の設定ファイル /etc/rancher/rke2/config.yaml を以下のように作成。
server: https://yassan-cp01.internal:9345 token: SYfnuawdPNXGEqnGPWGIM/WJy3wYV1Pixd2gRwL7hTA=
後はサービス起動して待つだけ。
# systemctl daemon-reload # systemctl enable --now rke2-agent.service # journalctl -u rke2-agent -f
これで終わりです。後は、適当なノードでkubectl get node できればOK
export KUBECONFIG=/etc/rancher/rke2/rke2.yaml /var/lib/rancher/rke2/bin/kubectl get nodes
以下のコマンド集が便利です。
RKE2 commands
Kuibeconfigの準備
以下を参考に用意します。
yassan-cp01.internal の /etc/rancher/rke2/rke2.yaml にクレデンシャル情報があるのでそこを参考に以下を今後作業するKubernetesクラスタの外のNodeのKubeconfigに追加。
- cluster: certificate-authority-data: LS0tLS1CRUd(略) server: https://yassan-cp01.internal:6443 name: yassan.local - context: cluster: yassan.local user: yassan.local name: yassan.local - name: yassan.local user: client-certificate-data: LS0tLS1CR(略) client-key-data: LS0tLS1CRUdJTiBFQ(略)
後は、kubectlのcontextを切り替えて kubectl get nodes が確認出来たら完了です。
Flink Kubernetes Operatorのセットアップ
続いてFlink Kubernetes OperatorのQuick Startを参考にセットアップしていきます。
また、Namespaceは以下とします。
- Flink Kubernetes Operator: flink-operator
- Flinkジョブ用: flink-a
また、今後の作業はKubernetesクラスタの外のノードから実行します。
cert-managerのインストール
まずは、Webhookコンポーネントを追加できるようにcert-managerのインストール
$ kubectl create -f https://github.com/jetstack/cert-manager/releases/download/v1.8.2/cert-manager.yaml
S3に対応するためイメージを変更
S3互換ストレージのバケット(s3a://)を使いたいので、Flinkのコンテナイメージに Hadoop S3 File Systems pluginsを追加する。
書いてるときりがないので、以下のリポジトリを参考にしてください。
イメージはPushしてるのでビルドもめんどい方はこちら。
S3クレデンシャルの追加
FlinkログなどはS3互換ストレージに記述したいので、S3クレデンシャルをSecretでNamespace flink-operator と flink-a に追加
--- # secret-s3-iam.yaml apiVersion: v1 kind: Secret metadata: name: s3-iam type: Opaque data: AWS_ACCESS_KEY_ID: Q(略) AWS_SECRET_ACCESS_KEY: K(略)
$ kubectl -n flink-operator -f secret-s3-iam.yaml $ kubectl -n flink-a -f secret-s3-iam.yaml
Flink Kubernetes Operatorのインストール
ドキュメントの通り、 helm repo add flink-operator-repo https://downloads.apache.org/flink/flink-kubernetes-operator-<OPERATOR-VERSION>/ しても良いんですが、テンプレートの構造を見たりvalueがどう使われるか見たい&ちょっとだけいじりたいことが多々あるので、HelmチャートはDLしてから使います。
$ curl -f -sL --retry 3 "https://github.com/apache/flink-kubernetes-operator/archive/refs/tags/release-1.10.0.tar.gz" | tar xz
Helmチャートは flink-kubernetes-operator-release-1.10.0/helm/flink-kubernetes-operator にあります。
HelmチャートのValueは以下のようにしました。
❯ diff オリジナルvalues.yaml 改変後values.yaml 23a6,8 > watchNamespaces: > - "flink-a" > - "flink-b" 26c11 < repository: ghcr.io/apache/flink-kubernetes-operator --- > repository: docker.io/yassan/flink-operator 28,30c13,14 < tag: "c703255" < # If image digest is set then it takes precedence and the image tag will be ignored < # digest: "" --- > tag: "1.10.0-1" > 47c31 < create: false --- > create: true 76a61,66 > - name: "HTTP_PROXY" > value: "http://proxy.example.com:8080" > - name: "HTTPS_PROXY" > value: "http://proxy.example.com:8080" > - name: "NO_PROXY" > value: "localh(略)" 79a70,71 > - secretRef: > name: s3-iam 165a158,166 > > fs.s3a.aws.credentials.provider: com.amazonaws.auth.EnvironmentVariableCredentialsProvider > s3.endpoint: http://minio:9000 > s3.path.style.access: true > > high-availability.type: kubernetes > high-availability.storageDir: s3a://flink-test/recovery > > jobmanager.archive.fs.dir: s3a://flink-test/flink-history
📝 values.yamlのの中身 📝
--- watchNamespaces: - "flink-a" - "flink-b" image: repository: docker.io/yassan/flink-operator pullPolicy: IfNotPresent tag: "1.10.0-1" imagePullSecrets: [] replicas: 1 strategy: type: Recreate rbac: create: true nodesRule: create: true operatorRole: create: true name: "flink-operator" operatorRoleBinding: create: true name: "flink-operator-role-binding" jobRole: create: true name: "flink" jobRoleBinding: create: true name: "flink-role-binding" operatorPod: priorityClassName: null annotations: {} labels: {} env: - name: "HTTP_PROXY" value: "http://proxy.example.com:8080" - name: "HTTPS_PROXY" value: "http://proxy.example.com:8080" - name: "NO_PROXY" value: "localhost,127.0.0.1,(略)" envFrom: - secretRef: name: s3-iam nodeSelector: {} affinity: {} tolerations: [] topologySpreadConstraints: [] resources: {} webhook: resources: {} operatorServiceAccount: create: true annotations: {} name: "flink-operator" jobServiceAccount: create: true annotations: "helm.sh/resource-policy": keep name: "flink" operatorVolumeMounts: create: false data: - name: flink-artifacts mountPath: /opt/flink/artifacts operatorVolumes: create: false data: - name: flink-artifacts hostPath: path: /tmp/flink/artifacts type: DirectoryOrCreate podSecurityContext: runAsUser: 9999 runAsGroup: 9999 operatorSecurityContext: {} webhookSecurityContext: {} webhook: create: true keystore: useDefaultPassword: true defaultConfiguration: create: true append: true flink-conf.yaml: |+ # Flink Config Overrides kubernetes.operator.metrics.reporter.slf4j.factory.class: org.apache.flink.metrics.slf4j.Slf4jReporterFactory kubernetes.operator.metrics.reporter.slf4j.interval: 5 MINUTE kubernetes.operator.reconcile.interval: 15 s kubernetes.operator.observer.progress-check.interval: 5 s # S3クレデンシャルは AWS_ACCESS_KEY_ID と AWS_SECRET_ACCESS_KEY を使うので以下とする fs.s3a.aws.credentials.provider: com.amazonaws.auth.EnvironmentVariableCredentialsProvider s3.endpoint: http://minio:9000 s3.path.style.access: true high-availability.type: kubernetes high-availability.storageDir: s3a://flink-test/recovery jobmanager.archive.fs.dir: s3a://flink-test/flink-history log4j-operator.properties: |+ # Flink Operator Logging Overrides # rootLogger.level = DEBUG # logger.operator.name= org.apache.flink.kubernetes.operator # logger.operator.level = DEBUG log4j-console.properties: |+ # Flink Deployment Logging Overrides # rootLogger.level = DEBUG metrics: port: nameOverride: "" fullnameOverride: "" jvmArgs: webhook: "" operator: "" operatorHealth: port: 8085 livenessProbe: periodSeconds: 10 initialDelaySeconds: 30 startupProbe: failureThreshold: 30 periodSeconds: 10 postStart: {} tls: create: false secretName: flink-operator-cert secretKeyRef: name: operator-certificate-password key: password
あとは以下の要領でインストール。
$ export FLINK_OP_NS=flink-operator
$ export DIR_HELM_CHARTS=/home/yassan/flink/flink-kubernetes-operator-release-1.10.0/helm/flink-kubernetes-operator
$ export DIR_HELM_VAL=/home/yassan/flink
$ kubectl create ns ${FLINK_OP_NS}
# マニフェストを生成(チェック用)
$ helm template ${FLINK_OP_NS} ${DIR_HELM_CHARTS} -n ${FLINK_OP_NS} -f ${DIR_HELM_VAL}/values_flink-operator.yaml > ${DIR_HELM_VAL}/manifest_${FLINK_OP_NS}_$(date '+%Y-%m-%d_%H%M%S').yaml
# インストールチェック
$ helm install ${FLINK_OP_NS} ${DIR_HELM_CHARTS} -n ${FLINK_OP_NS} -f ${DIR_HELM_VAL}/values_flink-operator.yaml --dry-run 2>&1 | tee ${DIR_HELM_VAL}/${FLINK_OP_NS}_dry_$(date '+%Y-%m-%d_%H%M%S').yaml
# インストール実施(初回)
$ helm install ${FLINK_OP_NS} ${DIR_HELM_CHARTS} -n ${FLINK_OP_NS} -f ${DIR_HELM_VAL}/values_flink-operator.yaml 2>&1 | tee ${DIR_HELM_VAL}/${FLINK_OP_NS}_$(date '+%Y-%m-%d_%H%M%S').yaml
# インストール実施(2回目以降)
$ helm upgrade ${FLINK_OP_NS} ${DIR_HELM_CHARTS} -n ${FLINK_OP_NS} -f ${DIR_HELM_VAL}/values_flink-operator.yaml 2>&1 | tee ${DIR_HELM_VAL}/${FLINK_OP_NS}_$(date '+%Y-%m-%d_%H%M%S').yaml
# アンインストール
$ helm delete ${FLINK_OP_NS} -n ${FLINK_OP_NS}
# チェック
$ helm ls --all-namespaces
Flinkジョブの実行
以下を参考にサンプルのFlinkジョブを実行していきます。
手順としては、FlinkDeploymentリソースを作成してapplyすればOK。
--- # basic.yaml apiVersion: flink.apache.org/v1beta1 kind: FlinkDeployment metadata: name: basic-example spec: image: docker.io/yassan/flink:1.20.0-1 flinkVersion: v1_20 flinkConfiguration: taskmanager.numberOfTaskSlots: "2" rest.flamegraph.enabled: "true" serviceAccount: flink jobManager: resource: memory: "2048m" cpu: 1 podTemplate: spec: containers: - name: flink-main-container env: - name: "HTTP_PROXY" value: "http://proxy.example.com:8080" - name: "HTTPS_PROXY" value: "http://proxy.example.com:8080" - name: "NO_PROXY" value: "localhost,(略)" envFrom: - secretRef: name: s3-iam taskManager: resource: memory: "2048m" cpu: 1 podTemplate: spec: containers: - name: flink-main-container env: - name: "HTTP_PROXY" value: "http://proxy.example.com:8080" - name: "HTTPS_PROXY" value: "http://proxy.example.com:8080" - name: "NO_PROXY" value: "localhost,(略)" envFrom: - secretRef: name: s3-iam job: jarURI: local:///opt/flink/examples/streaming/StateMachineExample.jar parallelism: 2 upgradeMode: stateless
マニフェスト作成出来たらあとはapplyして、FlinkDeploymentリソースをKubernetesクラスタに反映するだけ。
$ kubectl -n flink-a apply -f basic.yaml
すると、Flink Kubernetes Operatorが検知して、Flinkジョブとして、専用のJob ManagerとTask Managerが起動してワークロードを実行します。
今回は、 upgradeMode: stateless としているので、設定が変わると毎回からの状態からやり直しになってしまう一番簡単な本番利用向きではない簡単なジョブとなってます。もちろん、本番を意識したupgradeModeもありますが、今回はここまで。
Flink Cluster自体についても、今回のようにFlinkジョブごとにクラスタ構成するといったFlinkでいうところの Application Modeや一度起動したJob Managerを使いまわしてFlinkジョブを実行するSession Modeもあります。イメージは下図の通り(真ん中のやつはdeprecatedなので触れません)。
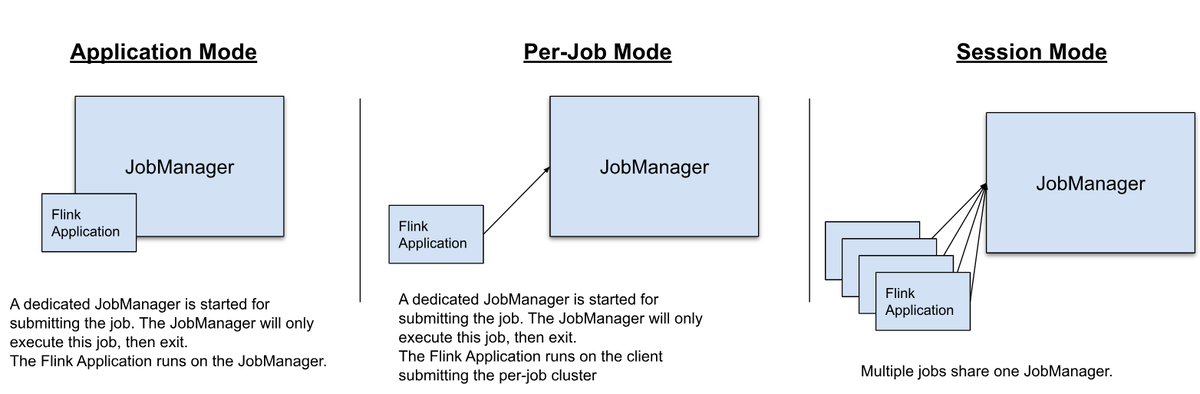
他にも以下にサンプルがあるので気になる方はサンプルを見るとイメージが付きやすいです。
話を実行中のFlinkジョブに戻します。
実行時のログは以下で見えます。
$ kubectl -n flink-a logs -f deploy/basic-example
また、起動中のFlinkジョブのFlink Dashbord は以下で見えます。
$ kubectl -n flink-a port-forward svc/basic-example-rest 8081
本番を想定した場合は、Ingressが用意されているのこちらを使えば良いです。
Ingress | Apache Flink Kubernetes Operator
いらなくなったら以下で削除出来ます。
$ kubectl -n flink-a delete flinkdeployment/basic-example
最後に
いかがだったでしょうか。
Flinkの設定が全然いじれてないので、状態を保存出来るS3は用意出来てるので、今後はいじってみて機会があったら続編を書きます。
(Flink Kubernetes OperatorやFlink自体のHA、モニタリング、アラート、アップグレード、Flinkジョブのリソース制御などなど)
以上、MicroAd Advent Calendar 2024 と Distributed computing (Apache Spark, Hadoop, Kafka, ...) Advent Calendar 2024 の25日目の最終日の記事でした。
-
言い訳
色々調べていくうちに面白くなって調べすぎて時間を結構そこに取られたのと、当初はZooKage使ってRancher Desktop環境にOzoneやHDFS立ち上げてS3バケットやHDFS用意して、そこにFlinkの環境を入れて、、とかやる予定だったんですが、、、記事書くためのブラウザ多数とDesktopのKubernetes環境だと、うちのマシンが非力すぎてメモリが足りなくなってしまい、Swap用意して逃したりもしたんですが、やってられんってことでやめました。。
Zookageはほんと簡単に手元で環境を簡単にスピンアップ出来るのでとっても便利なので、みんな使って欲しい。 kustomization.yaml で使わないものをコメントアウトして./bin/upするだけで立ち上がってきます。
ただし、Desktop環境を前提としてるのでPVCはローカルホストのパスを直接使ったりするのでDocker DesktopやRancher DesktopなどのDesktop環境以外ではそのまま使えないので注意です。
ブラウザ開き過ぎマンなのでメモリは32GBか64GBは欲しいですね。ブラウザでメモリごっそり持っていかれるのが辛い。。 zookage.github.io↩ -
Certified Kubernetes DistributionとしてCNCFに取り上げられている公式のKubernetesディストリビューション。流れさえ分かれば簡単にスピンアップ出来る便利なやつです(K3sも導入はだいぶ似てます)。Rancher必須でもないし、SUSEだからSUSEのOSじゃないとダメってこともないので安心して使って欲しい。
こまかい導入な話は2022のアドカレで記事にしてるのでそちらも是非、、
yassan.hatenablog.jp↩ -
Flink Forward 2024の他のセッション動画の一部が以下で公開されているので、今回のセッションも出てこないかなぁと期待しましょう。
youtube.com↩ - Ververicaは、Alibabaが買収したData Artisansの現状の社名↩
-
以下がドキュメント。
docs.rke2.io↩