この記事は Distributed Computing Advent Calendar 2025 の1日目の記事です。
今年もアドカレの季節がやってきました🎄
今回は、Apache Spark(以降、Spark)のKubernetes Operatorについて取り上げます。
Sparkは大規模データ処理には欠かせないミドルウェアで、Apache Iceberg の実行エンジンとしても利用されています。また、SparkのKubernetes Operatorは、Kubernetes上でSparkジョブのデプロイ・管理・スケーリングを自動化するためのOperatorです。
他にもストリーム処理の実行エンジンの代表格の Apache Flink にも、Kubernetes Operatorはありますが、これについては去年取り挙げたので興味があれば参照ください。 yassan.hatenablog.jp
さっそくSpark の Kubernetes Operatorの話をする前に、以下の構成に分けて解説していきます。
- Spark on Kubernetes を理解する(理解編) ※今回の記事
- Spark Kubernetes Operatorを動かしてみる(実践編)
- k3d を使ってマルチノードの環境でSpark on K8sを手元で試してみる
では、理解編を始めていきます。
また、ここでは、 Sparkは、 v4.0.1 を前提とします。
- なぜ今Spark on K8sか?
- Sparkアプリケーションの仕組みについて
- Spark on Kubernetesの仕組み
- 本番運用を想定した場合の課題
- ポイント1:Driver / Executor のサイズ決め(JVM と K8s の辻褄合わせ)
- ポイント2:Executor の数を人力で決めるのはやめたい(DRA)
- ポイント3:ESS無しでシャッフルとどう付き合うか
- 複数のSparkアプリケーションリソースを良い具合に制御したい
- 次回予告:Kubernetes Operatorを使ったSparkアプリケーションのデプロイ
- まとめ と 次回予告
- 参考
なぜ今Spark on K8sか?
これまでのSparkアプリケーションは、Sparkクラスタに接続可能なクライアントノードからspark-submitコマンドを利用してSparkアプリケーションをデプロイしてきました。
この場合、専用のSparkクライアントノードが必要になり、クライアントノードを動かし続ける点においてリソース効率が良くないです。
そこで、SparkのKubernetes Operatorでは、kubectlでKubernetesのSparkアプリケーションリソースをマニフェストで作成することで、Kubernetesクラスタ内部のOperatorがspark-submitの手間を省いてくれるので、専用のSparkクライアントノードを用意せずに、手元の環境でSparkアプリケーションをデプロイ可能になります。
その他にも、Kubernetes OperatorはSparkアプリケーションをコンテナで稼働させるため、複数のSparkのバージョンを混在させた状態で利用できるといったメリットもあります。
Sparkアプリケーションの仕組みについて
Spark on Kubernetesの前に、Sparkアプリケーションについて簡単に説明します。Sparkについてご存じの方は次の項目まで読み飛ばしてください。
Sparkアプリケーションは 図1 の様な構成になっています。
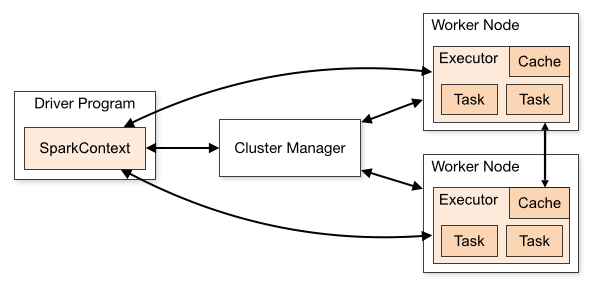
(Sparkドキュメント Cluster Mode Overview より引用)
Sparkアプリ=Driver × 1 + Executor × N の集合
Sparkアプリケーションは、アプリケーション毎に、上図の様に、1つのDriverと1個以上のExecutorで構成されます。
ユーザーが書いたメインプログラムがDriverとなり、ここで SparkContext を作り、クラスタ上の Executor たちに処理を割り振っていきます。 Executorは「そのアプリケーション専用」のJVMプロセス郡で、タスクを並列実行し、キャッシュや シャッフル1 といった中間データを保存します。アプリごとに Executor が独立するので、アプリ間でデータを直接共有せず、必要なら個々のExecutorから外部ストレージに書き出します。
他にも、Sparkの大事な概念である ジョブ、ステージ、タスク、シャッフル、パーティションについては Apache Spark徹底入門 をぜひ参照してください。
DriverやExecutorのリソースの管理は Cluster Manager にて行う
Cluster Managerは、Spark自身が提供するスタンドアロン、HadoopのYARN、Kubernetesに対応しており、どれを使っても基本アーキテクチャは同じです。
DriverのメインプログラムにあるSparkContextはCluster Managerと接続し、Cluster ManagerがDriverやExecutorのリソース(コア数やメモリサイズ、Executorの数)を調整します。
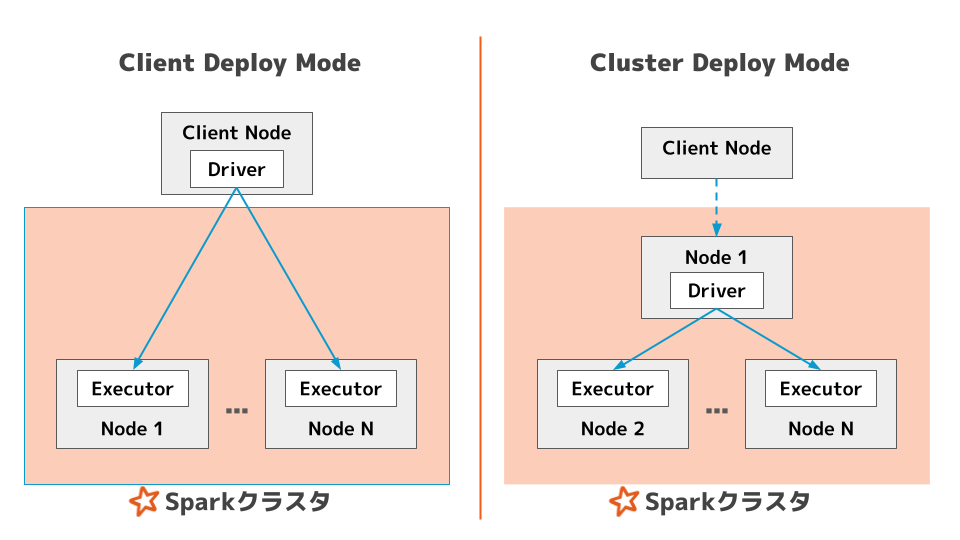
デプロイモードは 2 種類
Sparkアプリケーションの実行モードは、2種類あります。
- Cluster モード=Driver がクラスタ内で起動(リモート実行)
- Client モード=
spark-submitを実行したクライアント側で Driver が動く
どちらのモードでも、Driver は Executor からの接続を受けられる様にする必要があります。
実行・監視まわりの基本
Sparkアプリケーションのデプロイは spark-submit で行い、Driver には 専用のWeb UI が用意されています(通常は4040 番ポートで公開)。 ジョブ→ステージ→タスクの粒度で進捗を確認できます。アプリ内でのリソース配分は Spark のスケジューラ(フェア/FIFO など)で制御します。
補足
さらに詳しい情報は、以下を参考にしてください。
- Cluster Mode Overview - Spark 4.0.1 Documentation
- Job Scheduling - Spark 4.0.1 Documentation
- Apache Spark徹底入門
Spark on Kubernetesの仕組み
KubernetesでSparkアプリはどの様にして起動するのかについて説明します。Sparkアプリケーションの構成は、Kubernetes上でも同じです。Kubernetes上のSparkアプリケーションは、DriverやExecutorは個々にPodとして実行されます。
Kubernetes上にSparkアプリケーションをデプロイするのは、基本的にこれまでと同様に spark-submit を利用します。
Spark Piをクラスターモードで実行する場合の例:
$ ./bin/spark-submit \ --master k8s://https://<k8s-apiserver-host>:<k8s-apiserver-port> \ --deploy-mode cluster \ --name spark-pi \ --executor-memory 2G \ --num-executors 10 \ --class org.apache.spark.examples.SparkPi \ --conf spark.kubernetes.authenticate.driver.serviceAccountName=spark \ --conf spark.executor.instances=5 \ --conf spark.kubernetes.container.image=docker.io/library/spark:4.0.1 \ local:///path/to/examples.jar \ 5000
コマンドを実行すると図3の様にDriverポッドとExecutorポッドがデプロイされます。
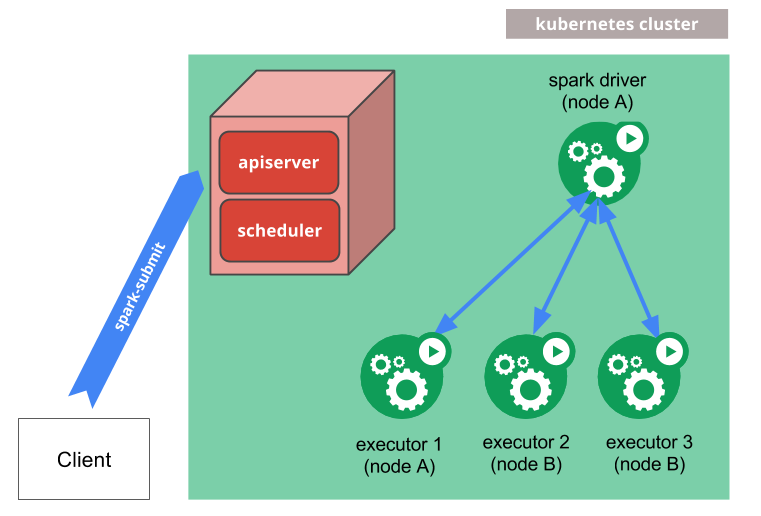
(Spark公式ドキュメント Running Spark on Kubernetes より引用)
次に 「submit → 起動 → 実行 → 終了」のライフサイクルをSparkアプリ開発者視点とKubernetes管理者視点で整理すると以下のようになります。
Sparkアプリ開発者視点で整理する
Sparkアプリ開発者視点(submit する人の目線)でSparkアプリケーションのライフサイクルを整理すると以下のようになります。
- 事前準備(最低限):
- Kubernetesクラスタへ到達出来る状態(
kubectl get poができる・RBAC権限あり)。Driver用のサービスアカウントには、Pods/Services/ConfigMapsの作成権限が必要です2 - 実行用Sparkコンテナイメージを用意
- Kubernetesクラスタへ到達出来る状態(
- Driverポッドの起動:
Sparkはまず、DriverをKubernetesポッドとして作成。このDriverが以降の全てを取り仕切ります(SparkSession/Contextの用意、Executorの立ち上げ等) - Executorポッドを必要数起動:
DriverはKubernetes APIを通じて、Executorポッドを作成し、接続してタスクを配布します。配置についてはKubernetesのスケジューラーが決めます。 - 実行中(タスク配布・シャッフル・スケール):
- ステージ間のデータ交換が発生すれば シャッフルが走ります
- Dynamic Resource Allocationの設定した場合、負荷に応じてExecutor ”数” が増減します(Spark側の設定)
- ログ・UI・デバッグ:
- Driver/Executorのログは各ポッドのログとして確認(
kubectl logs) - 実行中のDriverからSpark UI へアクセスする方法は、Spark公式ドキュメントのIntrospection and Debuggingを参照
- Driver/Executorのログは各ポッドのログとして確認(
- Sparkアプリケーションの完了とクリーンアップ:
完了時はExecutorポッドは終了・クリーンアップされるが、Driverポッドは”Completed”のステータスのまま残存(ログ確認の為)。リソースは消費しませんが、手動で掃除が必要です。
Kubernetesクラスタ管理者視点で整理する
Kubernetesクラスタ管理者視点(運用する人の目線)でSparkアプリケーションのライフサイクルを整理すると以下のようになります。
- 事前準備
- バージョン互換性(K8s、
kubernetes-clientライブラリ、DNS)と、RBAC(Driverポッドのサービスアカウントに Pods/Services/ConfigMapsの作成権限あるか)を事前確認 - デフォルトのセキュリティ関連の設定はゆるゆる状態。
USER/runAsUser/PodSecurity/hostPath制限など、自分のKubernetes環境に合わせて整備が必要 - オブジェクトストレージを利用出来るように事前にSparkアプリケーションのコンテナイメージに必要なライブラリを入れておく必要がある3
- バージョン互換性(K8s、
spark-submit受付(Kubernetes APIサーバ経由)- コマンド実行者の
spark-submitが apiserver に到達し、Driverポッドが作成される。ここで使用されるイメージは事前配布済みレジストリ上にある必要がある(Pull権限・Secret等も確認)
- コマンド実行者の
- スケジューリング&配置制御
- kube-scheduler が Driver/Executor の配置先ノードを決定。必要に応じて nodeSelector / (anti)affinity / tolerations / topologySpreadConstraints でテナント分離や配置制約を与える
- nodeSelector はSpark側から設定が可能だが、他についてはPod Templateを使って指定する4
- kube-scheduler が Driver/Executor の配置先ノードを決定。必要に応じて nodeSelector / (anti)affinity / tolerations / topologySpreadConstraints でテナント分離や配置制約を与える
- リソース・ネットワーク設定
- Requests/Limits、ServiceAccount、ConfigMap/Secret/Volumes を適切に付与する
- Requests/Limits といったCPU・メモリなどのリソース割り当ては必ず指定する。
- 実行中の管理
- Driver/Executorのログは各ポッドのログとして確認(
kubeclt logs) - 監視について、メトリクス・ログ収集は Prometheus/Grafana、FluentBitなどを利用する。メトリクスはJMXを使って公開出来るのでPrometheusの JMX Exporterの Java Agentを利用すると良い5
- Driver/Executorのログは各ポッドのログとして確認(
- 終了処理・後片付け
- Executor Pods は自動的に終了/削除。Driverポッド は Completed で残存(リソース消費なし)。Driverポッドが残り続けるので運用方針に応じて 手動クリーンアップを行う。
本番運用を想定した場合の課題
Sparkのカスタムコンテナイメージの作成がめんどい
Sparkのコンテナイメージはdocker.io/library/spark:<ver> としてSpark公式のコンテナイメージがあります。
ただし、本番運用を想定する場合、環境に応じて、必要になるライブラリやJARも異なってくるのでカスタムコンテナイメージが必要になります。
Spark公式からDownloadしたファイルを展開すると docker-image-tool.sh として、コンテナイメージを作成するツールもあります。詳しくは Docker Images|Running Spark on Kubernetes - Spark 4.0.1 Documentationに記載があります。
ただし、CIに組み込みにくいので、spark-docker/4.0.1 at master · apache/spark-docker にあるDockerfileを参考に自分で作成することをオススメします。
理由としては、何をやっているのか見通しにくい点や、CIで効率よくビルドする事を考慮しだすと、Dockerfileから作る方が楽だったりします。
また、CIでコンテナイメージを作成した際は、作成したコンテナイメージを実行(run)して、挙動確認のテストも忘れずに。
Spark on Kubernetes の「3 大ややこしポイント」
Sparkのコンテナイメージの他にも、Sparkアプリケーション開発者 / Kubernetesクラスタ管理者の両者にとってややこしポイントが大きく 3 つあります。
- 1 Pod(Driver / Executor)のサイズをどう決めるか
- 以下の両方の考慮がややこい
- JVM 的なメモリ(heap / off-heap)
- Kubernetes 的な Request / Limit
- 以下の両方の考慮がややこい
- Executor を何個にするかをどうやって決めるか
- ジョブごとに固定値をチューニングするのは辛いので以下をどう使うかがややこい
- Dynamic Resource Allocation(DRA)や
- Stage Level Scheduling(SLS)
- ジョブごとに固定値をチューニングするのは辛いので以下をどう使うかがややこい
- シャッフルをどう扱うか
- External Shuffle Service(ESS)が Kubernetes では未実装なので以下をどうするかがややこい
- シャッフルデータをどこに置き
- Executor / ノードが落ちてもどうやって耐えるか。
- External Shuffle Service(ESS)が Kubernetes では未実装なので以下をどうするかがややこい
今回は仕組みを全部説明せずに、以下に絞って整理します。
- そこで何が課題になるのか
- 本番で使うにはどのように考え、設定に落とし込めば良いのか
ポイント1:Driver / Executor のサイズ決め(JVM と K8s の辻褄合わせ)
TL;DR
- 1 Executor = 1 JVM = 1 Pod として、JVM と Pod のメモリを同じ「合計値」で見積もる
- Heap だけではなく、
memoryOverheadをきちんと積む(PySpark / UDF / Arrow があるなら手厚く) - Kubernetes の
requests/limitsをサボると、QoS 的に負けて Evict / OOMKill されやすい
まず「合計メモリ」を合わせる
Spark on Kubernetes ではざっくり次の対応です。
DriverとExecutorの両方を個別に設定が必要です。Executorを例にとると以下の通り。
- 1 Executor = 1 JVM プロセス = 1 Pod
- JVM(Spark)側
spark.executor.memory… Heapspark.executor.memoryOverhead… Heap 以外(JVMメタスペース / ネイティブ / PySpark など)
- Kubernetes 側
resources.requests.memoryresources.limits.memory
なので、Executor 1 つあたりの「実際に使うメモリ」は:
Executor メモリ合計
= executor.memory + executor.memoryOverhead
として、この値が Pod の memory request / limit にちゃんと乗っているか をまず揃えます。
ここがズレていると、
- Spark 的にはまだ余裕 → でも K8s 的には OOMKill
- あるいはその逆
という「二重会計事故」が起きます。
同様にしてDriverについても検討します。
⚠️オマケ:CPUとメモリの値のフォーマットに注意
SparkとKubernetesで微妙にCPU・メモリの値を指定する際のフォーマットが異なるので注意。
CPUの単位
Kubernetesの様にSparkを指定するとエラーになるので注意。
- Spark : 並列度の指定
- 整数値のみ。例:1, 2, 4
- Kubernetes : リソース要求の指定
- 整数 および 少数 の指定、 m(ミリ)の指定もOK 6
- 例: 1, 2, 4, 0.5, 100m(=0.1)
メモリの単位
Sparkに合わせて、Kubernetesも10進で統一しておく方が無難。ここを混ぜると数%〜十数%レベルでズレるので注意。また、単位の記述フォーマットは、Sparkは小文字 だが、Kubernetesは大文字なので注意。
- Spark:
- 2進のみ7
mormb(mebibytes),gorgb(gibibytes),tortb(tebibytes)
- Kubernetes:
- 以下の通り、2進でも10進どっちでもOK8 (これが危ない)
Mi/Gi… 2 進(1Gi = 10243)M/G… 10 進(1G = 109)
- 以下の通り、2進でも10進どっちでもOK8 (これが危ない)
設定のしかたはユースケースで考える
細かい理論より、まずはユースケースを起点に考えるとよいです。最低限このレベルで十分です。
Executor サイズを決める際の指針
- タスク 1 個に欲しい Heap の目安を置く(例:0.5、1 GiB)
spark.executor.cores(同時実行タスク数)を決めるspark.executor.memory≒ (タスク数 × 1タスクあたり Heap) + αspark.executor.memoryOverhead
Kubernetes 側は「QoS を落とさない」が基本
spark.kubernetes.executor.request.cores/.limit.coresspark.kubernetes.executor.request.memory/.limit.memory
は 基本的に request = limit で揃えて Guaranteed を狙うのがおすすめです。
- Request を絞りすぎて
Burstable/BestEffortにすると、- ノード逼迫時に 優先的に Evict されがち
- 「なんか頻繁に落ちる」の原因になりやすい
最低限これだけはチェックしておく
本番投入前に、次だけ見ておけばだいたい大事故は避けられます。
- Executor / Driver の 合計メモリ(heap + overhead) と Pod の memory request / limit は一致しているか?
- PySpark / Arrow / UDF を多用しているのに、
memoryOverheadをデフォルトのままにしていないか? - Executor を巨大にしすぎて GC に苦しんでいないか?
- 「コアを盛る」より「そこそこの大きさの Executor を複数」のほうが扱いやすいことが多いです
Sparkアプリケーションの実行中ならWeb UIから細かい情報を確認できますが、別途、Monitoring and Instrumentation - Spark 4.0.1 Documentation を参考に、History Serverを常時稼働させて、Sparkアプリケーションの状況をチェックしたり、Prometheusを使ってメトリクスをモニタしながら想定通りの動きになるか確認しながら進めることをオススメします。
ポイント2:Executor の数を人力で決めるのはやめたい(DRA)
TL;DR
YARNでは使えていた External Shuffle Service (ESS) がKubernetes では使えないので、DRA にESSの考慮を除外して検討する必要がある。
まずは以下を押さえる。
spark.dynamicAllocation.enabledspark.dynamicAllocation.min/maxExecutorsspark.dynamicAllocation.shuffleTracking.enabled
SLS(Stage Level Scheduling)は「ハマるジョブには強力だけど、副作用(Executor が溜まりがち)」問題がある(SLSについては後述します)。
Kubernetes で DRA を ON にするときの必須セット
K8s では ESS が使えないので、DRA を使いたいならspark.dynamicAllocation.enabled = true に加えて、大きく2パターンの選択肢があります。
パターン1:ExecutorのDecommission + シャッフル追跡
外部サービスなしで DRA を動かせる 一番シンプルな選択肢。
spark.decommission.enabled = true
spark.storage.decommission.shuffleBlocks.enabled = truespark.dynamicAllocation.shuffleTracking.enabled = true- Executor が持つシャッフルデータを Driver がトラッキングし、データが必要な間は Executor を落とさないようにする
spark.dynamicAllocation.shuffleTracking.timeout- 設定して溜まり続けるのを防ぐ
パターン2:ExecutorのDecommission + ShuffleDataIO
シャッフルが重いワークロード向けのもう一段手厚い構成
spark.decommission.enabled = true
spark.storage.decommission.shuffleBlocks.enabled = truespark.shuffle.sort.io.plugin.classで ShuffleDataIO プラグインを指定- 例:
KubernetesLocalDiskShuffleDataIO- ローカルディレクトリとして PVC をマウント(
spark-local-dir-*)し、シャッフル復元性を高める(emptyDirはエフェメラルなのでExecutorがkillされると揮発する) - 詳細は Local Storage | Running Spark on Kubernetes - Spark 4.0.1 Documentationを参照
- ローカルディレクトリとして PVC をマウント(
- あるいは Celeborn などの Remote Shuffle Service
- 例:
この組み合わせの狙いは、以下。
Executor を Decommission するタイミングで、シャッフルを 別 Executor やストレージに逃がす。 そもそもシャッフルを Executor ローカルだけに閉じ込めない(ShuffleDataIO)ので、Executor / Pod / ノードをかなり積極的に減らしてもシャッフル再計算コストを抑えつつ DRA を回しやすい。
DRAに関連するドキュメントや設定項目は以下なので詳しくはここを読んでください。
- マニュアル:Dynamic Resource Allocation | Job Scheduling - Spark 4.0.1 Documentation
- 設定項目:Dynamic Allocation | Configuration - Spark 4.0.1 Documentation
ただ、いきなり全部は触らなくても、まずは、shuffleTracking 単独 から始めればOK。
「maxExecutors をやたら大きくしない」かつ「shuffleTracking 有効にする」だけでも、
「固定 Executor 数からの卒業」 という意味ではだいぶ楽になります。
次に、ここで触れている ExecutorのDecommission や SLS、 ShuffleDataIO について解説します。
Decommission は「縮退時のクッション」
DRA とセットで効いてくるのが Graceful Decommission9 です。
- OFF のまま:
- Executor を減らすときにいきなり kill → タスク再実行 / シャッフル再計算が増える
- ON にすると:
- 「この Executor を捨てるよ」と宣言
- シャッフル / キャッシュを別 Executor に逃がしてから終了
特に、
- Spot / Preemptible ノード
- Cluster Autoscaler でノードを削る
ような環境では、「ノードを消す前に中身を逃がす」ために Decommission を ON にしておく価値が高いです。
Stage Level Scheduling(SLS)は「使いどころ限定だけど強い武器」
SLS10 は Stage ごとに「Executor の形」を変えられる機能です。
- 前処理 Stage:メモリ多め / コア少なめ
- 学習 Stage:コア多め / メモリ普通
といった「ステージごと最適化」ができますが、K8s + DRA では注意点があります。
Kubernetes では ESS がないので spark.dynamicAllocation.shuffleTracking.enabled が前提
その結果、古い Stage 用の Executor も「シャッフルデータ持ち」の間は消せない。
つまり、Executor が溜まりやすい(IdleTimeout でも減りにくい)。必要な場合は、 spark.dynamicAllocation.shuffleTracking.timeout を設定する(ただし、再計算の可能性が出てくる)。
なので、 導入時は 「SLS を入れたら、Executor の総数が前より増えてないか?」 を必ずメトリクスで見る、くらいの慎重さが必要です。
他にも、PodTemplate のリソースは default profile のみに有効です。
つまり、カスタム ResourceProfile ではテンプレのリソースは伝播しないため、CPU/メモリ/GPU など ResourceProfile 側に必ず明記する必要があります。
実装内容については、Sparkのソースのテスト見るとイメージがつきやすいかも。ここ) とか ここ)。
ポイント3:ESS無しでシャッフルとどう付き合うか
Sparkアプリケーションにて、 reduceByKey、join、repartitionといった操作は、Executor・ノード間でデータをコピーして、各パーティション内のデータの“並び”を作り直し、キーごと・条件ごとにデータを作業しやすい配置に再分配するシャッフルが発生します。
この操作は、データ量に応じて、メモリだけでなく、ネットワーク帯域やDisk I/Oが多く消費されるので高コストな処理になります。
そこでSparkには 外部シャッフルサービス(External Shuffle Service, ESS)という仕組みがあります。これは、 各ノード上で常駐する“外部シャッフル配信プロセス” で、Executor が消えても、そのノードのローカルディスク上にある シャッフルファイルを代理配信してくれる仕組みです。
Cluster Managerに YARNを使う場合は NodeManager の Auxiliary Service として ESS を常駐させられるため、DRAと相性よく動かせます。 しかし、Spark公式ドキュメントにFuture Workとして記載されてる通り、現在でもESSはKubernetesでは未実装となっています。
では、ESS無しでどうするかについて解説していきます。
TL;DR
Kubernetes では ESS がないので、以下を組み合わせる事になる。
- shuffleTracking / Decommission
- ローカル / 永続ストレージの選択
- (必要なら)Celeborn / Uniffle などのリモートシャッフル
3-1. まずは「デフォルト構成 + ちょっと厚め」の構成
最初の一歩として現実的なのはこれです。
- ストレージ:
emptyDir(ローカル SSD があればなお良し) - DRA:ON
spark.dynamicAllocation.shuffleTracking.enabled = truespark.decommission.enabled = true+spark.storage.decommission.shuffleBlocks.enabled = true
これだけでも、
Executor をある程度減らしつつ、
シャッフル再計算の回数を抑え
外部サービスを増やさずに運用
という「シンプル寄りだけど現実的」な構成になります。
3-2. 「シャッフルがとにかく重いジョブ」向けの厚め構成
それでも、
シャッフルが TB オーダー
再計算が現実的じゃない
といったジョブなら、もう一段厚くします。
- Executor ローカルを PVC ベースにする
spark.kubernetes.executor.volumes.persistentVolumeClaim.*をspark-local-dir-*にマウント
- ShuffleDataIO を Kubernetes 向けに
spark.shuffle.sort.io.plugin.class=org.apache.spark.shuffle.KubernetesLocalDiskShuffleDataIO
- Decommission を有効化して、
- Executor / ノード削除前にシャッフルを逃がす
このパターンは、
ストレージコスト
ネットワークレイテンシ
PVC の数
など運用コストが一気に上がるので、「本当にそこまでやる価値があるワークロードだけ」 に絞るのが現実的です。
3-3. さらに先:Celeborn / Uniffle などのRemote Shuffle Serviceを使う構成
最後は「専用のシャッフルクラスタに逃がす」パターンです。
Apache Celeborn / Apache Uniffle などを使うと、
- シャッフルデータを別クラスタに置ける
- Executor は軽く作って軽く捨てる、という構成が取りやすい
メリット: - DRA / Decommission と非常に相性が良く、Executor をかなり大胆に増減できる
デメリット: - シャッフルクラスタの設計・監視・運用がまるごと増える
結論としては:
まずは「emptyDir + shuffleTracking + Decommission」
→ ダメなら「PVC + KubernetesLocalDiskShuffleDataIO」
→ それでも足りない超大規模シャッフルだけリモートシャッフルを検討
くらいの 3 段階で考えると、チームの負担と得られるメリットのバランスが取りやすいです。
複数のSparkアプリケーションリソースを良い具合に制御したい
ここまでは個々のSparkアプリケーションに関する課題について解説してきました。
しかし、本番を想定した場合、クラスタ上には複数のSparkアプリケーションが常時稼働することになるので、個々のSparkアプリケーションを効率よくスケジュールする必要があります。
例えば、以下のようなケースです。
- システムAのバッチとシステムBのバッチがあった場合、システムAにリソースを多く割り当てたい
- システムAのバッチ1をSubmitしたいが、クラスタに空きがないので、しばらく待って優先度の低いシステムBのバッチのSparkアプリケーションをPreemptionする
- Driverと必要最小限のExecutor数が確保出来てから、Sparkアプリケーションをアロケーションしたい(いわゆるギャングスケジューリングの話。KubernetesはSparkアプリケーションがDriver・Executorで1セットになることを考慮しないので、クラスタに空きがあればExecutor1個だけでもスケジュールするがこれは無駄)
そこに対応するのが、Apache YuniKornです。こちらについては、前にアドカレで紹介しました。
Spark公式ドキュメントでも紹介されています。YuniKorn以外にも CNCFプロジェクトの Volcano も紹介されています。
最新の情報は、KubeConでの発表もあるので参考にしてください。
KubeCon + CloudNativeCon Europe 2025: A Comparative Analysis of Kueue, Volcano
次回予告:Kubernetes Operatorを使ったSparkアプリケーションのデプロイ
ここまで、Sparkアプリケーションの特徴を説明し、Kubernetes上にSparkアプリケーションをデプロイする方法について説明してきました。
本番のSparkアプリケーションを考慮すると、SparkのプロパティやKubernetes向けの設定(ConfigMap、Secret、監視やObservability向け)など、更に細かい設定が必要になります。また、CLIベースのデプロイなので、Kubernetesを生かしたコード化もやりにくいです。
また、実行したいSparkアプリケーションに合わせて spark-submit CLIを個別に用意するのも手間がかかります。 他にも、DriverポッドにTTL(時間が立つと削除される)が設定できないので、本番定期的にDriverポッドを削除する仕組みを用意する必要も出てきました。
そこで、面倒な運用の解決策として、Spark向けのKubernetes Operatorが用意されています。Operatorがあることで、Kubernetesのマニフェストでこれらの設定を用意して、 kubectl apply するだけでSparkアプリケーションのsubmit、Driverポッドの後片付けまで実施出来ます。
代表的なSparkのKubernetes Operatorには以下の3つがあります。
- https://github.com/kubeflow/spark-operator
- https://github.com/apache/spark-kubernetes-operator
- https://github.com/stackabletech/spark-k8s-operator
次回は、これらのSpark Kubernetes Operator のうち、上の2つについて紹介していきます。
まとめ と 次回予告
いかがだったでしょうか。SparkとSpark on Kubernetesについてイメージ出来たでしょうか。
(-_-).。oO(ホントは、Operatorの話まで書く予定だったのですが、ボリュームがデカくなりすぎたので次回にします。)
次回は、Spark Operatorの説明と、実際にk3dを使って手元でマルチノード環境を作り、Sparkアプリケーションをデプロイしてみて、紹介した2つのOperatorを比較しながら、動作感・運用しやすさ・ハマりどころなどを中心に掘り下げていく予定です。
以上、 Distributed Computing Advent Calendar 2025 の1日目の記事でした。
Distributed Computing Advent Calendar 2025 の2日目にSparkのカスタムコンテナイメージを作成する際に面倒な依存JARを楽に取得するTipsを紹介します。お楽しみ(?)に。
また、Distributed Computing Advent Calendar 2025の枠が空いてるので参加お待ちしてます!
参考
- Running Spark on Kubernetes - Spark 4.0.1 Documentation
- Job Scheduling - Spark 4.0.1 Documentation
- Configuration - Spark 4.0.1 Documentation
- Monitoring and Instrumentation - Spark 4.0.1 Documentation
- 【Java】JVMにおけるメモリ管理とガベージコレクションについて #Java - Qiita
- Spark ジョブの動的リソース割り当てを構成する - Container Service for Kubernetes - Alibaba Cloud ドキュメントセンター
- Apache Hadoop Amazon Web Services support – Hadoop-AWS module: Integration with Amazon Web Services
- Getting Started - Prometheus Operator
- Java Agent exporter | JMX Exporter
- Monitoring Spark Applications with Prometheus and JMX Exporter | Kubeflow
- Spark Shuffle Service (External). Ways to handle large-scale-shuffle in… | by Amit Singh Rathore | Dev Genius
- Apache Celeborn
- Apache Uniffle
- Apache YuniKorn
- Sparkの「シャッフル」は、同じ種類のデータをまとめるために計算途中のデータを複数のコンピュータ間で大量に並べ替えて送り合う処理で、通信や読み書きの負荷が大きくなります。↩
-
Driverポッドがポッド、サービス、および ConfigMap を作成するので必要な権限を持つサービスアカウントの作成も事前に必要です。コマンドでは
--conf spark.kubernetes.authenticate.driver.serviceAccountName=sparkとして、事前に作成済のsparkという名前のサービスアカウントを指定しています。
詳しくは RBAC | Running Spark on Kubernetes - Spark 4.0.1 Documentation を参照ください。↩ - AWS S3またはS3互換ストレージを利用したい場合は、 Hadoop-AWS module を利用するため、必要なJARが必要になります。Google CloudのGCSなども同様に、別途、Cloud Storage Connectorの用意が必要になります。面倒なJARファイルの用意について、明日のDistributed Computing Advent Calendar 2025 の記事で用意しましたのでそちらを参考にしてください。↩
-
nodeSelector については、--conf spark.kubernetes.node.selector.[labelKey] の様にして指定出来る。DriverやExecutorで区別して指定することも可能。
(anti)affinity / tolerations / topologySpreadConstraints の様な更に突っ込んだ設定は、Pod Template)を事前に定義してS3などに配置しておき、Driverポッドなら--conf spark.kubernetes.driver.podTemplateFile=s3a://bucket/driver.ymlの様にして指定する。詳細は SparkのPod Templateに関するドキュメントを参照。↩ -
Sparkが公開するメトリクスについては公式ドキュメントを参照。
設定するには、まず、JMX Exporterの Java AgentのJARをSparkのコンテナイメージに同梱しておいて、--conf "spark.driver.extraJavaOptions=-javaagent:/path-to-jmx_prometheus_javaagent.jar=8090:/path-to-driver-config.yml"の様に指定してSparkアプリケーションを実行してメトリクスを公開する。そして、Prometheus OperatorのPodMonitorまたはServiceMonitorを使ってPrometheusからスクレイプ出来るようにする。↩ - CPUの単位|コンテナおよびPodへのCPUリソースの割り当て | Kubernetes↩
- この辺り。 Spark Properties | Configuration - Spark 4.0.1 Documentation↩
- Kubernetesのリミットとリクエストについて理解する | Sysdig または メモリーの単位|コンテナおよびPodへのメモリーリソースの割り当て | Kubernetes↩
- Graceful Decommission of Executors | Job Scheduling - Spark 4.0.1 Documentation↩
- SLSの説明はこれ Stage Level Scheduling Overview | Running Spark on Kubernetes - Spark 4.0.1 Documentation。 PySparkのAPI:pyspark.resource.ResourceProfile — PySpark 4.0.1 documentation↩